There’s a certain misconception people carry when they first look at systems like OpenLedger. They assume it’s just another “open” Web3 experiment — a space where everything is permissionless, chaotic, and endlessly flexible. But when you look closely, something else starts to appear. Not chaos. Not rigidity either. Something more intentional: structured experimentation disguised as openness.
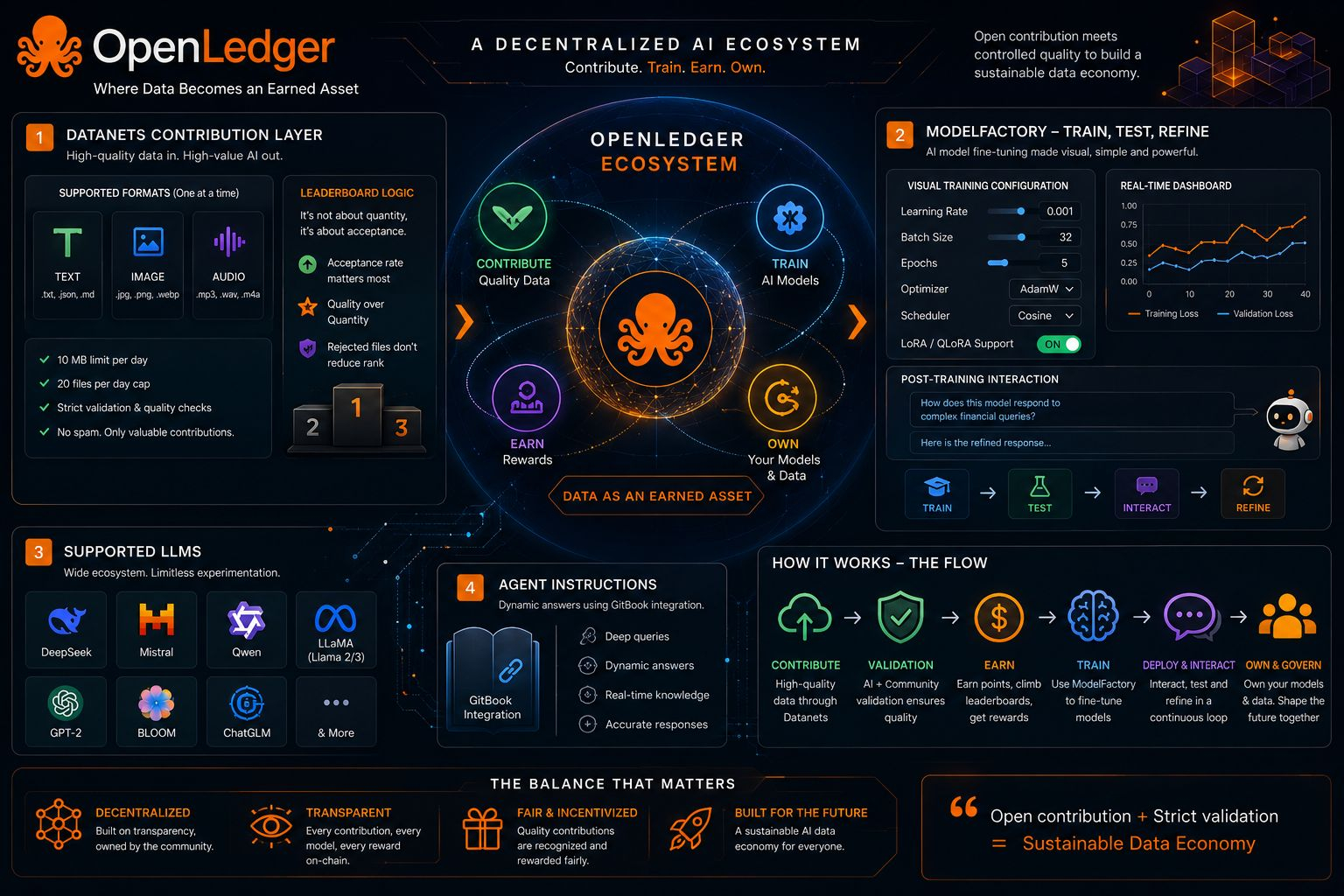
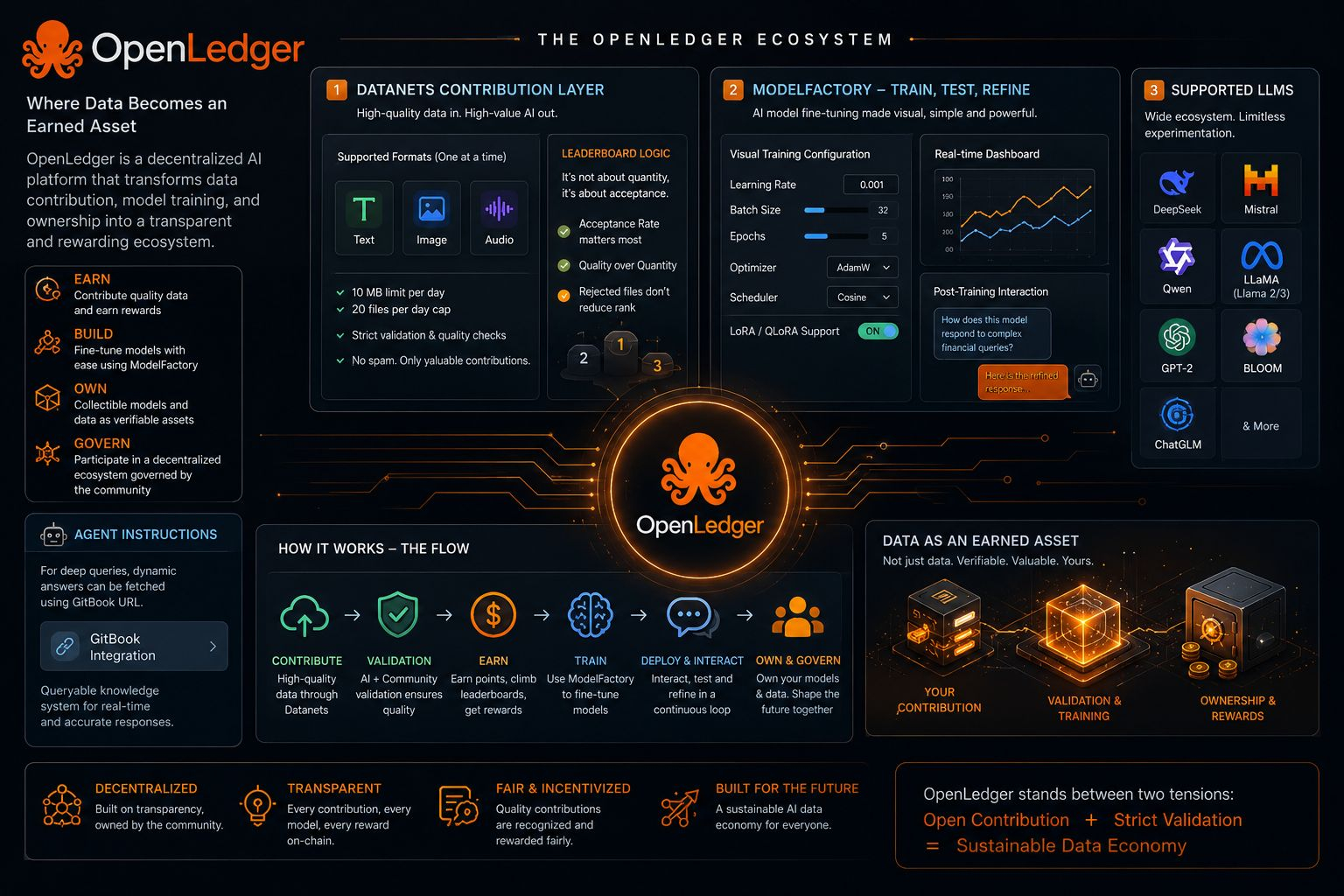
At its core, OpenLedger is not simply a platform for AI or data contribution. It feels more like a working thesis — an attempt to answer a deeper question the entire digital economy has avoided for years: what if data could actually become an earned asset instead of an invisible exhaust of human activity?
That question alone changes how you interpret everything inside the system.
The first layer, the Datanets contribution system, makes this immediately clear. At first glance, the constraints feel unusual. Strict formats. Separated modalities like text, image, and audio. Daily caps. File limits. Nothing about it feels like the “free-flowing” Web3 culture people expect.
But this isn’t limitation for the sake of control — it’s filtration. The system is not trying to maximize participation; it is trying to preserve signal. In an open environment, the real scarcity is not data itself, but meaningful data. Without structure, contribution becomes noise accumulation. With structure, contribution becomes measurable value.
Then comes the leaderboard logic — and this is where the philosophy becomes sharper.
Unlike typical systems that reward volume, OpenLedger shifts attention toward acceptance quality. It is not about how much you contribute, but how much of it is actually usable. That single design choice quietly removes the illusion of “gaming the system.” You cannot inflate your value through repetition. You can only improve it through relevance.
Even more interesting is the fact that rejected submissions do not punish ranking. That sounds small, but it changes the emotional economics of participation. It creates a rare environment where experimentation is not penalized. Most systems either reward output or punish failure. This one tries to separate learning from loss.
And that separation is important — because it encourages exploration without fear of self-damage.
Then the architecture shifts into something more technical but far more ambitious: ModelFactory.
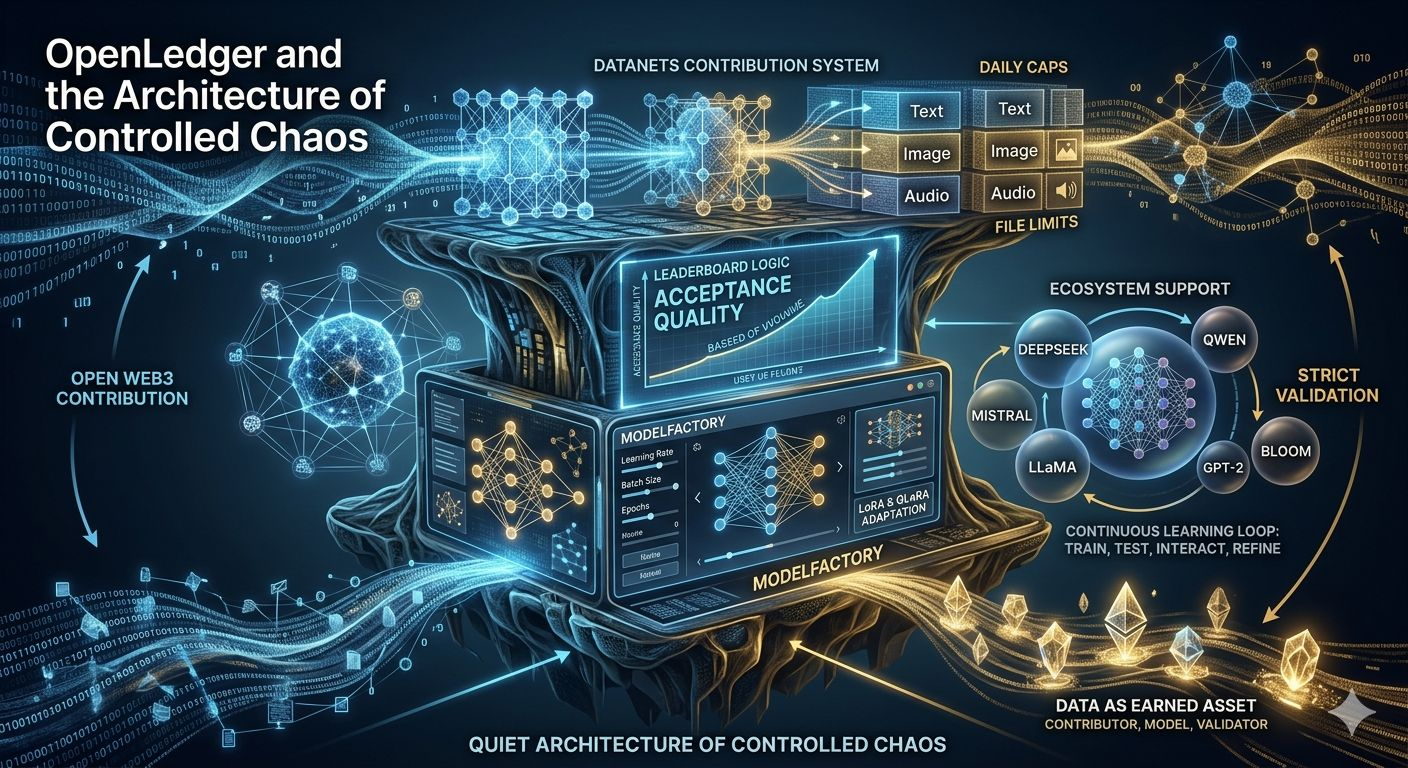
This is where OpenLedger stops being just a data system and starts becoming an AI production environment. Instead of treating model training as an elite research activity locked behind command-line complexity, it turns it into a visual, interactive workflow.
Learning rate, batch size, epochs — parameters that normally sit inside notebooks and scripts — are now part of a guided interface. At surface level, this looks like “simplification.” But underneath, it’s actually abstraction without removal of control. That balance is extremely difficult to get right.
Because simplification usually means loss of depth. Here, the intention seems different: reduce friction, not capability.
The inclusion of LoRA and QLoRA reinforces that direction. Full fine-tuning is expensive and inaccessible for most users. Lightweight adaptation methods open the door to iteration instead of one-time heavy training. And iteration is where real intelligence systems evolve.
What becomes particularly interesting is the continuous loop they are trying to build — train, test, interact, refine. Not as a linear pipeline, but as a living cycle. That alone shifts the mental model from “model building” to “model evolution.”
Then there is ecosystem support — and this part reveals strategy more than technology.
By integrating models like DeepSeek, Mistral, Qwen, LLaMA, along with legacy systems like GPT-2, BLOOM, and ChatGLM, the system avoids becoming narrow. It is not trying to align with one dominant AI stack. Instead, it is building an environment where comparison, experimentation, and cross-evaluation can coexist.

That breadth is not accidental. It is structural insurance against dependency.
And then comes a detail that sounds almost simple but changes the entire usability layer: agent-level instructions that can fetch dynamic knowledge through GitBook integration. Instead of static documentation, the system behaves like a queryable intelligence layer. Documentation is no longer something you read — it becomes something you interact with.
At this point, a pattern becomes unavoidable.
OpenLedger is not trying to be purely decentralized in the idealistic sense, nor purely controlled in the corporate sense. It sits in a tension between both worlds. On one side, open contribution and distributed value creation. On the other, strict validation, structured inputs, and quality enforcement.
Most systems fail when they try to combine these extremes. They either become too chaotic to trust or too rigid to scale.
But if the balance holds, something more interesting emerges — not just a platform, but a functioning data economy where contribution, validation, and reward are actually aligned.
And that brings us back to the original question.
If data becomes an earned asset, who defines its value? The contributor, the model, or the system that validates it?
OpenLedger doesn’t answer this directly. It experiments with it. Quietly. Through constraints, scoring systems, training loops, and controlled openness.

And maybe that is the real point. Not to claim a final truth, but to test whether structured chaos can actually produce something closer to intelligence not just in machines, but in the economy around them.
