

Il Futuro delle App e degli Agenti AI su OpenLedger
Argomento
Openledger
Tag
OpenLedger
Panoramica del Post
Da modelli specializzati a agenti che possono vedere, ragionare e agire — questo blog analizza come OpenLedger definisce il futuro degli agenti e delle applicazioni AI, con contesto, strumenti, memoria e logica integrati nella blockchain.
Nelle fasi iniziali del machine learning, la maggior parte dei sistemi erano costruiti come modelli monolitici addestrati una sola volta e poi congelati. Col passare del tempo, l'industria si è evoluta verso il fine-tuning e varianti specifiche per compiti. Questi modelli hanno posto le basi per l'adattamento al dominio, ma costruire applicazioni AI utili oggi significa potenziare il modello per fare di più.
Un modello potente è solo una parte dell'equazione. Affinché i sistemi AI operino in modo significativo nel mondo reale, devono comprendere il loro spazio problematizzante, interagire con dati live, recuperare contesto storico ed eseguire logica deterministica. Proprio come le GPU hanno sbloccato la scala per l'addestramento, il prossimo salto riguarda lo sblocco dell'interazione, dell'attribuzione e dell'allineamento economico a livello applicativo.
Questa è l'infrastruttura che OpenLedger fornisce.
OpenLedger è la blockchain AI. È progettata non come una chain di uso generale, ma come uno strato di esecuzione e attribuzione per sistemi intelligenti. Fornisce il substrato in cui modelli, dati, memoria e agenti diventano componenti interoperabili. Questo blog dettaglia gli strumenti che estenderanno i modelli per abilitare una vasta gamma di agenti e applicazioni aggiungendo il contesto, il comportamento e la memoria di cui hanno bisogno.
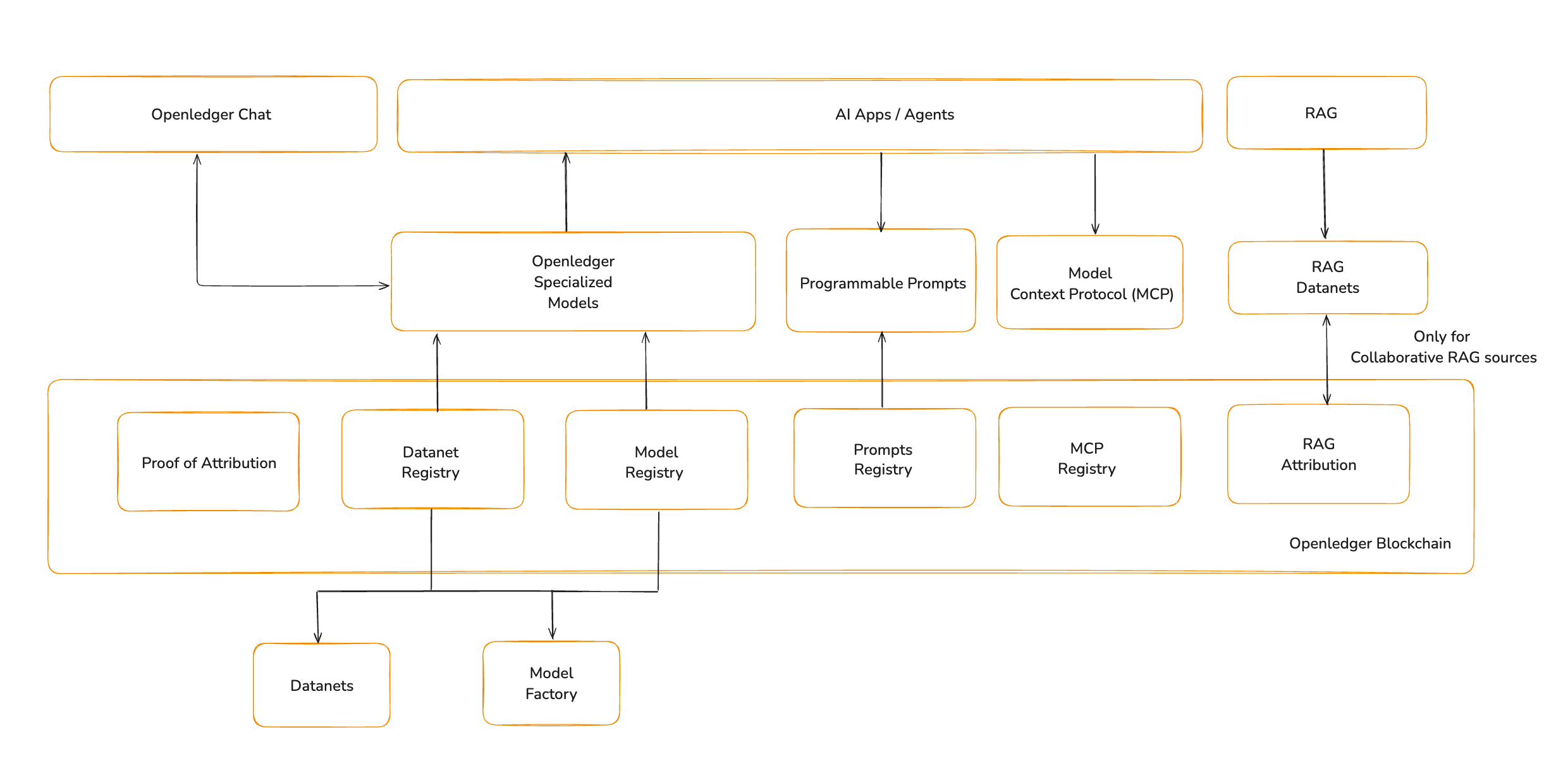
Modelli specializzati (un breve riepilogo)
La base di qualsiasi applicazione intelligente è un modello. I modelli di uso generale offrono flessibilità, ma quando applicati a domini specializzati, beneficiano notevolmente da un fine-tuning e adattamento. OpenLedger migliora questo processo attraverso una pipeline dedicata:
-> Datanets che sono repository di dati curati, collaborativi e attribuibili costruiti dalla comunità
-> Fabbrica di Modelli che semplifica il fine-tuning utilizzando flussi di lavoro senza codice
-> OpenLoRA che ospita varianti di adattatori economici che possono essere scambiati in tempo reale, rendendo l'inferenza leggera e componibile
Questi componenti sono stati discussi ampiamente in post precedenti. Servono come fondamento. E con le giuste estensioni, consentono l'emergere di agenti robusti e intelligenti.
Protocollo di Contesto del Modello (MCP)
Per un modello per aprire un file, leggere un database o invocare uno strumento, ha bisogno di accesso allo stato e al contesto esterni. Per dare ai modelli questa capacità, OpenLedger introduce il Protocollo di Contesto del Modello (MCP).
MCP definisce la struttura per fornire contesto a un modello e ricevere risposte strutturate che possono essere eseguite. Consiste di tre parti: un client che fornisce dati, un server che elabora le chiamate agli strumenti e un router che gestisce il flusso tra di essi.
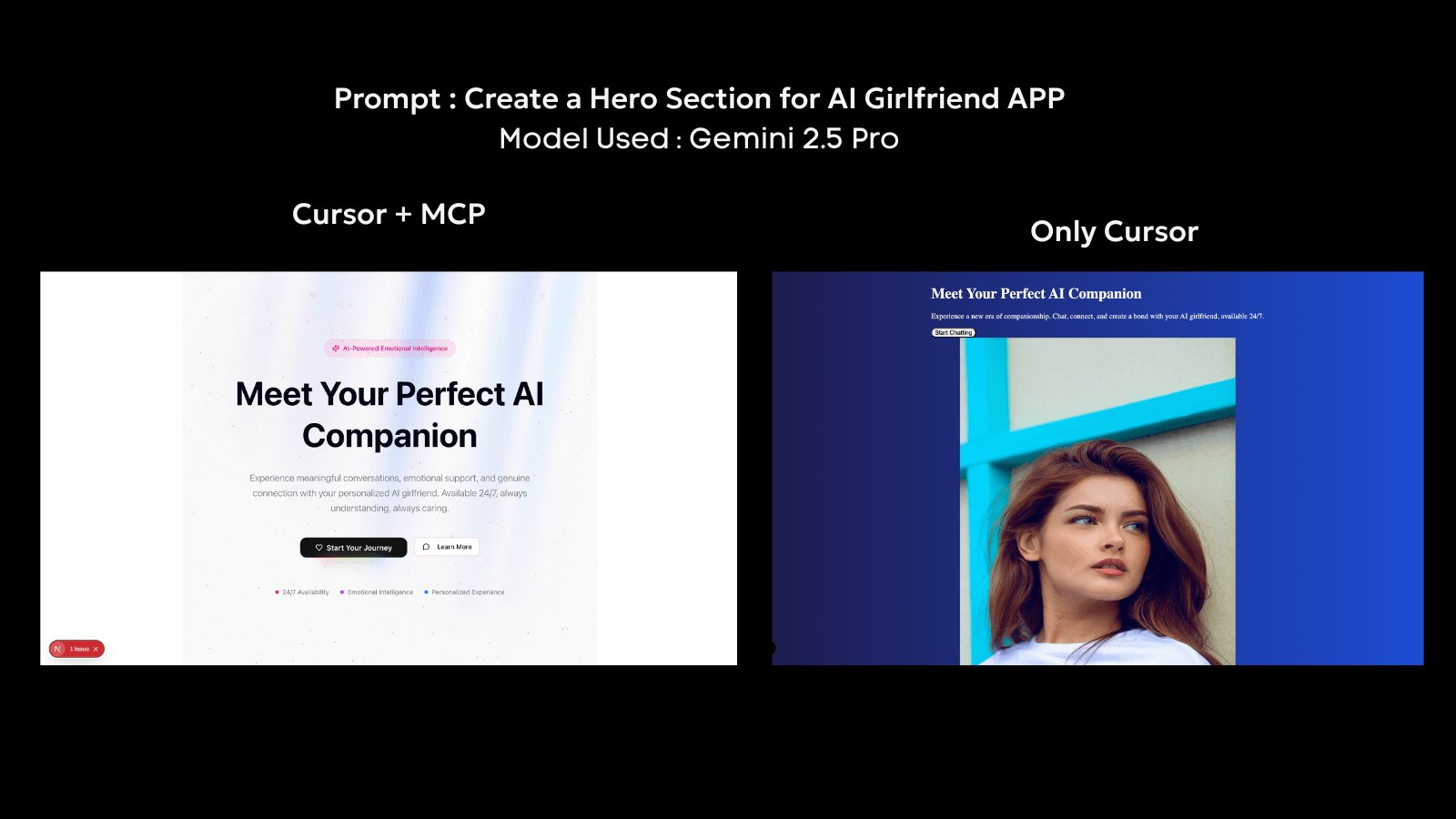
Nella pratica, MCP è già stato adottato in sistemi come Cursor, dove un agente può leggere file locali, modificare codebase e svolgere compiti basati su strumenti all'interno dell'ambiente di sviluppo. Strumenti come 21.dev fungono da clienti MCP che possono essere aggiunti a Cursor per creare interfacce dinamiche e in tempo reale. Utilizzando 21.dev, gli agenti ottengono la capacità di operare su componenti UI live, generando output che riflettono lo stato in tempo reale con uno strato visivamente ricco.
Visione futura per MCP con OpenLedger
OpenLedger prevede che MCP evolva in un registro onchain. Ogni strumento MCP può essere registrato, versionato e attribuito. Gli strumenti diventano componenti componibili che qualsiasi agente può invocare, con utilizzo registrato e ricompensato sulla blockchain. Questo consente agli sviluppatori di pubblicare lettori di file, renderer o client API, e farli chiamare da qualsiasi agente basato su OpenLedger con piena attribuzione e tracciabilità.
Generazione Aumentata da Recupero
Alcune conoscenze sono troppo grandi, troppo dettagliate o troppo frequentemente aggiornate per essere incorporate direttamente nei pesi del modello. Tuttavia, sono fondamentali per il ragionamento. La Generazione Aumentata da Recupero (RAG) estende la capacità di un modello introducendo una memoria specifica per la query in tempo reale.
RAG separa l'archiviazione dall'inferenza. I documenti sono incorporati in vettori, indicizzati semanticamente e recuperati a runtime in base alla query dell'utente. Il contenuto recuperato viene quindi iniettato nella finestra del prompt, ancorando la risposta del modello.
Questo metodo è particolarmente rilevante per agenti specifici del dominio. Un agente addestrato a comprendere un dominio particolare potrebbe accedere a post di blog, documentazione, proposte e thread della comunità. Invece di memorizzare tutto questo contenuto, interroga un sistema RAG costruito da fonti fidate. La risposta è accurata, aggiornata e ancorata a prove reali. Questa struttura consente agli agenti di evitare allucinazioni, mentre li abilita a cercare, recuperare e ragionare su contenuti dinamici.
Visione futura per RAG con OpenLedger
OpenLedger estende RAG in uno strato collaborativo e attribuibile. Proprio come con dataset e modelli, ogni documento archiviato in un indice RAG è attribuito al suo contributore. Quando il documento viene recuperato, quell'uso viene registrato. Questo trasforma RAG da un sistema di memoria a un meccanismo di incentivo.
In futuro, i contributori saranno in grado di registrare documenti on-chain come parte di un grafo di conoscenza distribuito. Ogni evento di recupero attiverà micro-attribuzioni, creando un flusso trasparente di credito e valore economico legato all'influenza informativa.
Un agente basato su OpenLedger addestrato su contenuti specifici della piattaforma come post di blog, documentazione, proposte di governance e conversazioni degli utenti non avrà bisogno di memorizzare tutto il contesto. Può interrogare un sistema RAG decentralizzato costruito da fonti comunitarie verificate. Ogni intervallo recuperato rimanda al suo autore, consentendo la distribuzione delle ricompense anche al momento dell'inferenza.
Con l'infrastruttura di OpenLedger, RAG diventa un sistema per un ragionamento verificabile e incentivato. Ogni paragrafo, citazione o punto dati può essere tracciato, riutilizzato e monetizzato in modi che riflettono la vera influenza nell'ecosistema degli agenti.
Prompt come logica comportamentale
Il livello finale di un agente intelligente è il suo comportamento. Questo non è codificato in pesi o dati. È definito attraverso i prompt.
Un prompt struttura l'interazione. Dice al modello come pensare, come formattare la sua uscita e quali vincoli seguire. Funziona come il livello logico che governa come vengono interpretati gli input e come vengono invocati gli strumenti. Negli agenti complessi, il design del prompt non è un'istruzione unica. Può coinvolgere catene di modelli strutturati, campi di contesto dinamici e istruzioni di pianificazione.
La progettazione dei prompt consente agli sviluppatori di definire il comportamento dell'agente senza modificare il modello stesso. Con il giusto design, gli agenti diventano deterministici nei loro passaggi di ragionamento. Le loro uscite rimangono coerenti, l'uso degli strumenti è delimitato e le risposte riflettono sia il contesto fornito che l'obiettivo previsto.
Visione futura per i prompt con OpenLedger
OpenLedger tratta i prompt come asset programmabili. In futuro, questo potrebbe portare a uno standard di smart contract per i prompt, consentendo loro di essere distribuiti, versionati e referenziati direttamente sulla blockchain. I prompt diventerebbero elementi fondamentali nello sviluppo degli agenti, con attribuzione e riutilizzabilità integrate nel loro design.
Un registro dei prompt su OpenLedger consentirebbe agli sviluppatori di creare e pubblicare template riutilizzabili legati a compiti, strumenti o modelli specifici. Questi template potrebbero essere collegati a agenti, aggiornati nel tempo e monetizzati in base all'uso.
Ogni prompt utilizzato da un agente potrebbe essere tracciato fino al suo autore. L'attribuzione sarebbe applicata a livello infrastrutturale, consentendo ricompense eque, coordinamento trasparente e interoperabilità a livello di comportamento tra gli agenti. I prompt non sarebbero più stringhe statiche ma componenti dinamici e verificabili dei sistemi intelligenti.
Caso studio: costruire un agente di trading addestrato dalla comunità su OpenLedger
Questo è come può essere costruito un vero agente di trading utilizzando OpenLedger. Inizia con i dati, costruisce il modello, aggiunge strumenti live e si trasforma in un'applicazione funzionante.
Passo 1: Raccolta di dati della comunità
Il processo inizia con un Datanet. Un Datanet è una piattaforma di collaborazione sui dati della comunità. I trader di Discord, Twitter e altre comunità contribuiscono con strategie di trading, annotazioni di grafico, analisi di token e decisioni di trading. Il proprietario del Datanet esamina e verifica ogni invio. Una volta approvati, i dati vengono aggiunti al Datanet e diventano parte di un dataset di istruzioni in crescita. Ogni contributore è registrato sulla blockchain.
Passo 2: Addestra un modello specializzato
Utilizzando i dati verificati dal Datanet, un modello viene affinato per comprendere i modelli di trading, come pensano i trader e come vengono prese le decisioni. Il modello viene distribuito utilizzando OpenLoRA. Questo mantiene il modello leggero, più economico da eseguire e facile da aggiornare.
Passo 3: Aggiungi contesto in tempo reale con MCP
L'agente ha bisogno di dati di mercato live per prendere decisioni. Attraverso il Protocollo di Contesto del Modello (MCP), si collega a:
-> CoinMarketCap per i prezzi dei token
-> Binance e Coinbase per scambi in tempo reale
-> Kaito per il mindshare di tendenza su Twitter
-> Uniswap o PancakeSwap per la liquidità on-chain
Ogni volta che uno strumento viene utilizzato, l'attribuzione viene registrata sulla blockchain.
Passo 4: Usa RAG per la memoria di mercato
L'agente ha anche bisogno di contesto storico. Utilizzando la Generazione Aumentata da Recupero (RAG), estrae informazioni come:
-> Whitepaper dei token
-> Proposte DAO
-> Decisioni di governance
-> Programmi di emissione
-> Registrazioni di exploit passati o eventi importanti
Questo fornisce all'agente una piena conoscenza di base sui token che analizza.
Passo 5: Definisci le regole dell'agente come prompt
I prompt dicono all'agente come combinare tutti i dati e prendere decisioni. L'agente controlla i prezzi, la liquidità, il sentiment e la storia dei token.
-> Se il sentiment è alto ma la governance è debole o ci sono problemi passati, segnala un alto rischio
-> Se la volatilità è alta e il sentiment è poco chiaro, aspetta.
-> Se i fondamentali e il sentiment sono forti, suggerisce un possibile ingresso.
I prompt sono versionati, riutilizzabili e completamente attribuiti.
Passo 6: Attribuisci tutto onchain
Ogni dataset, strumento, prompt e documento utilizzato dall'agente viene registrato su OpenLedger. I contributori ricevono automaticamente credito ogni volta che il loro lavoro alimenta una decisione dell'agente.
Il Risultato
I dati della comunità diventano un agente di trading completamente funzionante. Legge mercati live, comprende la storia dei token, applica ragionamenti e prende decisioni chiare. Tutto ciò che fa è trasparente, tracciabile e ricompensa ogni contributore coinvolto. Questo è come vengono costruiti gli agenti su OpenLedger.
