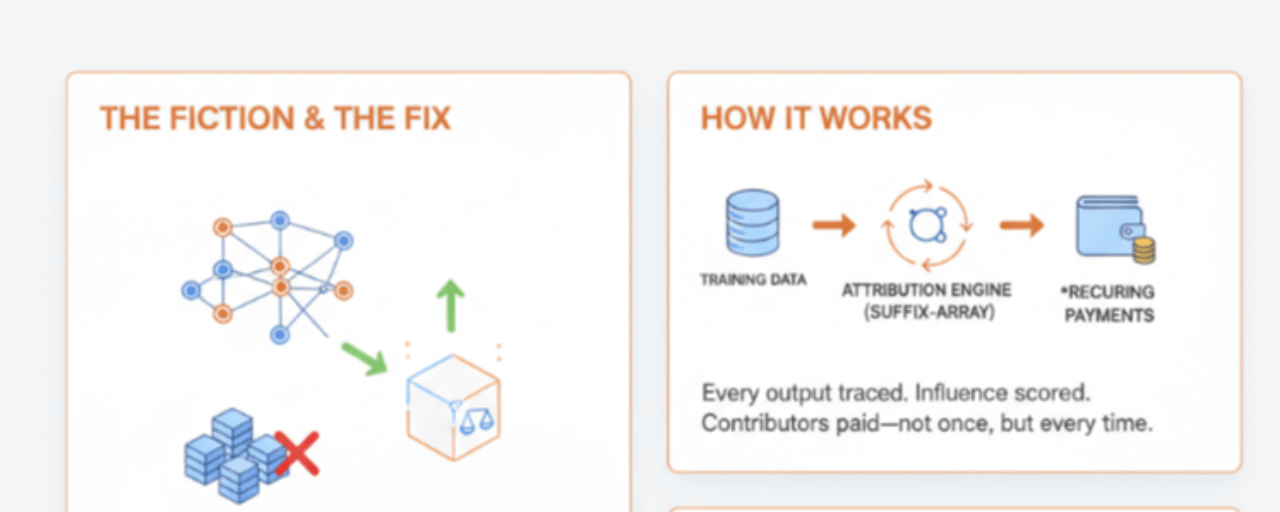

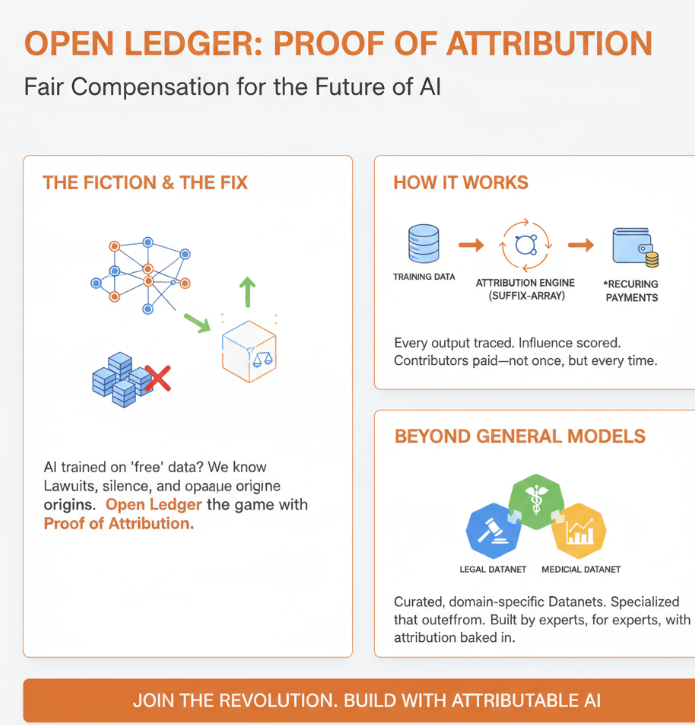
Ci sto pensando da un po' e continuo a tornare alla stessa conclusione. L'intero settore dell'IA si basa su una sorta di finzione educata. La finzione è che i dati di addestramento siano gratuiti, di pubblico dominio o correttamente concessi in licenza, e che le persone il cui lavoro ha plasmato questi modelli siano già compensate o non contino davvero. Tutti nel settore sanno che non è vero. Le cause legali lo rendono ovvio. Il silenzio dei principali laboratori di IA sulla questione della provenienza dei dati di addestramento lo rende ovvio. Il fatto che nessuno possa mostrarti effettivamente da dove proviene un output specifico di un modello lo rende estremamente ovvio.
La Proof of Attribution, che Open Ledger ha costruito nel suo protocollo di base, è la prima risposta tecnica seria a quella finzione che ho effettivamente visto implementata a livello infrastrutturale piuttosto che semplicemente descritta in un articolo di ricerca.
Ecco cosa fa realmente. Quando un modello addestrato sulla rete di Open Ledger produce un output, il sistema può tracciare quali parti dei dati di addestramento hanno influenzato quell'output utilizzando l'attribuzione dei token basata su array di suffissi. Non è una cosa semplice da costruire. Controlla gli output del modello rispetto a corpora di addestramento compressi per rilevare ciò che è stato memorizzato e ciò che è stato genuinamente sintetizzato. Il punteggio di influenza che esce da quel processo diventa la base per i pagamenti effettivi ai contribuenti i cui dati hanno guidato il risultato. Non una tariffa fissa per il caricamento. Non un pagamento una tantum. Un'attribuzione ricorrente ogni volta che i tuoi dati fanno qualcosa di utile.
Quella distinzione conta più di quanto probabilmente suoni. La maggior parte delle persone che contribuiscono dati a progetti IA attualmente non ottiene nulla. Gli accordi più generosi offrono una compensazione una tantum per l'accesso. Ciò che fa il modello di Open Ledger invece è trattare il contributo di dati più come proprietà intellettuale che continua a generare valore nel tempo. Se la tua conoscenza specializzata ha plasmato un modello che sta rispondendo a migliaia di domande, ottieni una parte di quell'attività indefinitamente.
Penso che il motivo per cui questo non riceva più attenzione sia che la maggior parte della conversazione intorno all'IA e alla crypto si concentra sul lato degli agenti, sul lato del prezzo del token, o sul lato infrastrutturale in termini di calcolo grezzo. Il livello di proprietà dei dati sembra meno entusiasmante fino a quando non ti rendi conto che in realtà è la parte portante dell'intera struttura. Senza dati di addestramento puliti, attribuibili, giustamente compensati, ogni modello IA costruito su questa infrastruttura ha un punto interrogativo legale ed etico che pende su di esso. Con esso, i costruttori ottengono qualcosa che attualmente non possono trovare da nessun'altra parte: una pipeline di addestramento che possono effettivamente difendere.
L'aggiornamento dell'Attribution Engine che è stato spedito a gennaio 2026 ha reso questo ancora più significativo assicurando che i collegamenti dati-output rimangano intatti anche mentre i modelli vengono aggiornati e affinati nel tempo. Questa è la parte che mi ha davvero colpito. I modelli non sono statici. Evolvono. I vecchi sistemi di attribuzione avrebbero perso il filo ogni volta che si verificava un'iterazione del modello. L'approccio di Open Ledger mantiene la catena di attribuzione continua indipendentemente da come il modello cambi dopo l'addestramento iniziale. È genuinamente difficile da fare e il fatto che funzioni significa che i contribuenti non vengono esclusi dai guadagni solo perché il modello che hanno aiutato ad addestrare è migliorato.
Non sto dicendo che questo sia un problema risolto in tutti i casi limite. Non lo è. Ma è il tentativo strutturale più onesto per risolverlo che esista in questo momento e per chiunque stia osservando la situazione dei dati di addestramento dell'IA con un certo livello di preoccupazione, questo conta.
Adesso sovrapponi Datanet specifici per dominio a questo e il quadro diventa ancora più interessante.
L'assunzione che la maggior parte delle persone porta all'addestramento dell'IA è che più dati siano sempre meglio. Questo è stato il paradigma dominante per un po'. Dataset più grandi, scraping più ampi, più token. Modelli generali addestrati su praticamente tutto hanno prodotto risultati impressionanti da generalisti e per un po' sembrava che fosse questo il gioco. Ma chiunque abbia realmente provato a usare un modello a scopo generale per lavori professionali specializzati ha incontrato un limite. Analisi legale, diagnosi mediche, modellazione finanziaria. Questi non sono compiti in cui sapere un po' su tutto ti porta dove devi andare. Hanno bisogno di modelli che siano stati addestrati sui dati giusti, curati da persone che comprendono il dominio, e affinati rispetto a standard che uno scraping generico di internet non può fornire.
Il sistema Datanet di Open Ledger è specificamente progettato per questo. Invece di un gigantesco pool di tutto, i Datanet sono pool di dati curati e specifici per dominio che i contribuenti costruiscono e mantengono. Un Datanet legale contiene giurisprudenza, strutture contrattuali, quadri normativi e il tipo di linguaggio carico di giudizi che proviene da professionisti che comprendono cosa conta. Un Datanet medico contiene note cliniche, letteratura di ricerca e schemi di ragionamento diagnostico a cui un modello generale non è mai stato esposto con alcuna profondità. Un Datanet finanziario contiene il tipo di analisi della struttura di mercato, linguaggio di modellazione del rischio e logica istituzionale che semplicemente non esiste nel volume o nella qualità necessari sul web aperto.
I modelli linguistici specializzati che vengono addestrati su questi Datanet superano i modelli generali nei compiti di dominio con un margine che non è nemmeno paragonabile. Questa non è una affermazione teorica. È il motivo per cui ogni serio deployment di IA aziendale che ho visto si sta spostando verso modelli specializzati affilati piuttosto che chiamate GPT grezze. La domanda è sempre stata da dove provengono i dati di addestramento di alta qualità specifici per dominio e chi ha l'incentivo di curarli e mantenerli. Il sistema di attribuzione di Open Ledger risponde a entrambe le parti di quella domanda simultaneamente. I dati provengono da professionisti che conoscono il dominio. Hanno l'incentivo a contribuire e mantenere la qualità perché vengono pagati ogni volta che quei dati producono un output utile.
Per settori come quello legale, medico e finanziario, questa combinazione è così significativa che penso cambi il calcolo tra costruire e comprare prodotti IA in quei settori. In questo momento, la maggior parte dei team di IA aziendali sta o scraping qualsiasi cosa riescano a trovare o pagando grandi somme per dataset proprietari con provenienza poco chiara. Il modello di Open Ledger offre un'opzione in più che ha l'attribuzione integrata, incentivi alla qualità integrati, e una storia di conformità che le prime due opzioni semplicemente non hanno.
