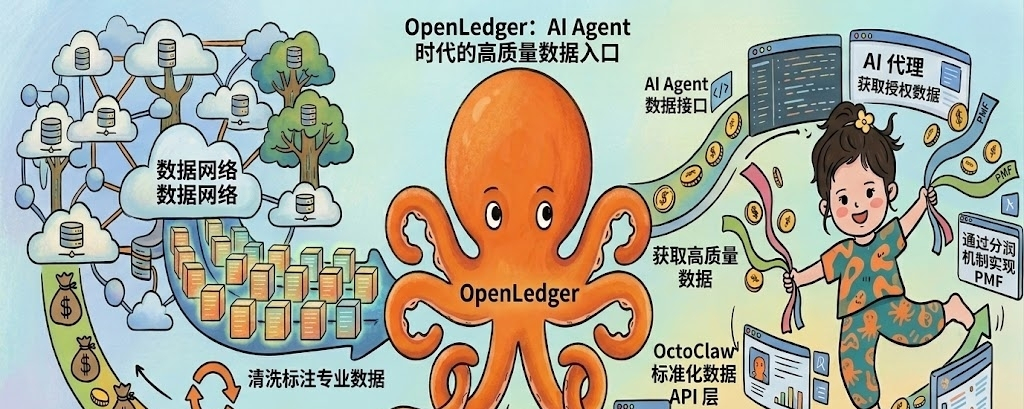
我最近花了不少时间在试各种AI Agent,整体感受是Agent能干的事越来越多,但有一个问题一直没人好好解决,就是Agent要拿到高质量数据这件事仍然是个死结。Agent本身的推理能力可以很强,但如果它能调用的数据都是公开网页爬来的二手信息,那它做出来的事就是堆叠搜索结果,谈不上真正的智能。@OpenLedger 今年推出的OctoClaw让我第一次觉得这个死结有机会被打开。
先说清楚OctoClaw是什么。它本质上是一个Agent调用#OpenLedger 链上Datanet的接口层,让任何AI Agent都能通过标准化的API从OpenLedger的Datanet里调取经过授权的高质量数据,调用的时候自动按Proof of Attribution分润给数据贡献者。这个设计听起来不复杂,但它解决的问题挺关键,Agent第一次有了一条合规获取专业数据的路径。
我五月这周做了一个小测试,用一个开源Agent框架接入了OctoClaw,让它从一个金融Datanet里调取过去三个月的链上交易数据来分析某个代币的鲸鱼行为,整个调用过程大概花了二十秒,Gas费加数据费一共扣了我大约0.3美金等值的OPEN代币,返回的数据质量明显高于我之前从公开区块链浏览器抓的数据,因为Datanet里的数据经过了贡献者的标注和清洗。
OctoClaw做的事情其实是给AI Agent时代搭建一个数据市场的基础设施。Agent经济要真正成立,前提是Agent能像人一样购买专业服务,包括购买数据、购买计算、购买其他Agent的能力,这套交易必须发生在一个低延迟、低成本、可审计的网络上,传统的Web2 API做不到这件事,因为Web2 API需要预先注册账号、绑定支付方式、走人工审批流程,Agent没法自动完成这些步骤。OctoClaw走链上路径绕开了这些环节,Agent持有钱包就能调用,调用一次扣一次费,没有账号体系也没有审批流程,这种纯机器友好的交易模式才是AI Agent真正需要的。
我以前看过几个项目想做Agent专用的数据市场,比如Fetch.ai、SingularityNET,它们的方向是对的但都卡在了同一个地方,就是数据供给不够多。一个数据市场最难的不是技术,是怎么让真正有价值的数据愿意进来,OpenLedger的Proof of Attribution分润机制刚好给了数据贡献者一个持续的激励,这跟Fetch.ai那种一次性交易的模型完全不同,OctoClaw继承了这个分润机制,意味着每一次Agent调用都会强化数据供给方的动机,让网络的飞轮转起来。
OctoClaw最大的问题是Agent生态本身还很早期,真正在生产环境里运转的Agent数量有限,OctoClaw能服务的需求规模目前还很小,我自己每天调用OctoClaw的次数也就个位数,要让OctoClaw成为基础设施级别的入口,前提是Agent行业先起来,这是个先有鸡还是先有蛋的问题,但从今年Anthropic、OpenAI在Agent方向的投入节奏看,Agent生态真正起量可能要到2027年下半年。数据质量的标准化也还没解决,OctoClaw能保证数据是从授权Datanet来的,但保证不了数据本身是高质量的,目前OpenLedger上的Datanet质量参差不齐,Agent调用之前需要自己做一层筛选,这层筛选目前没有自动化工具支持,全靠Agent开发者人工评估,这个体验对大规模采用是个阻力。性能瓶颈也是个挑战,AI Agent在很多场景下需要毫秒级的响应,OctoClaw目前通过OP Stack的L2加EigenDA返回数据的延迟在秒级,这个延迟对绝大多数Agent场景够用,但对高频交易、实时决策这类场景就不够了,未来要拓展到这些场景必须做专门的快速通道优化。
OctoClaw给AI Agent提供合规付费数据这件事一定会成为下一个时代的基础需求,OctoClaw是我目前看到的认真在做这件事的项目,光这一点就值得跟一段时间。但OctoClaw能不能真的成为AI Agent时代的入口,取决于两个外部因素,一个是Agent生态什么时候起量,另一个是数据市场标准化什么时候被业界接受,这两件事OpenLedger单方面推不动,必须等行业一起转向。对我个人来说,OctoClaw让我对$OPEN 的长期价值多了一份认可,因为它不只是一个数据归因协议。