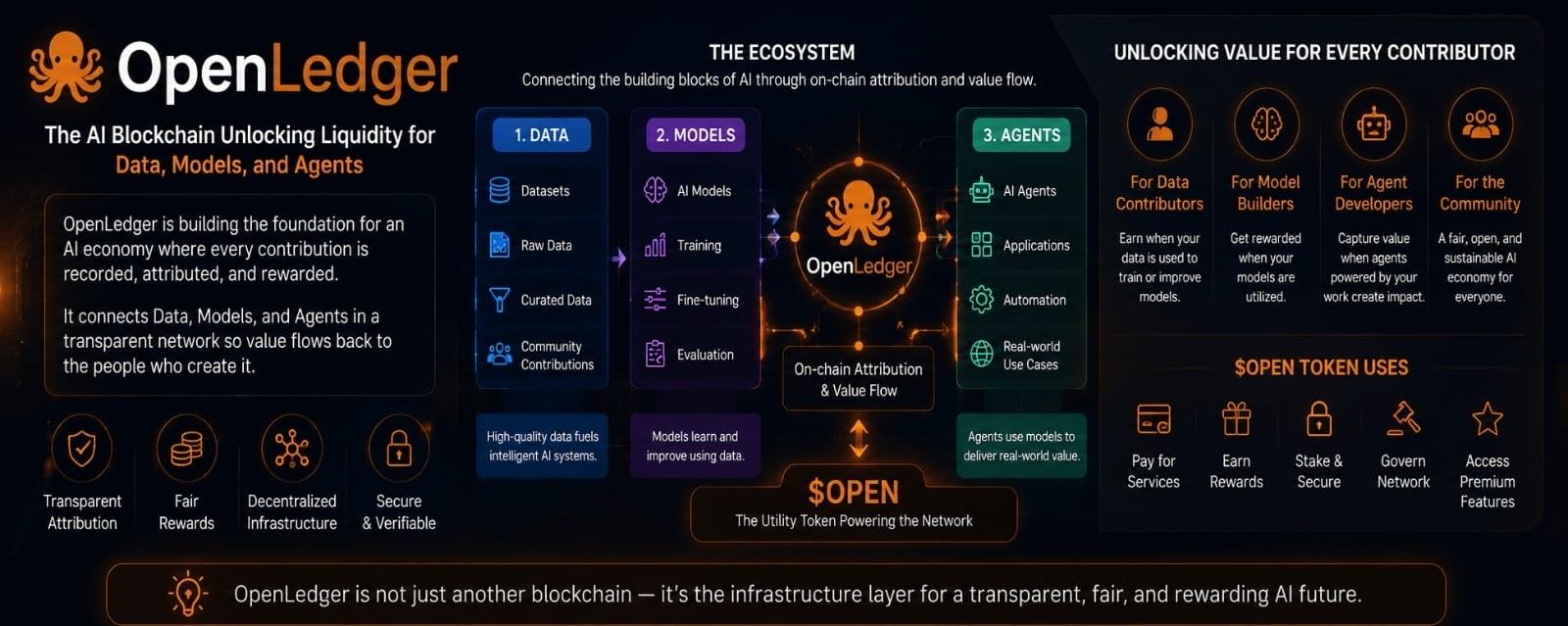
OpenLedger sembra un progetto costruito attorno a un problema che la gente di solito ignora fino a quando non inizia a costargli soldi.
Guarda, il crypto ha visto questo schema troppe volte. Un progetto lanciato. Tutti farmano punti. I wallet si moltiplicano da un giorno all'altro. Utenti finti inondano il sistema. Gli airdrop premiano il rumore invece del reale contributo. Le persone che hanno davvero aiutato a costruire, testare, fornire valore o portare attività utile spesso vengono trattate allo stesso modo di chi esegue script su cinquanta wallet.
Diventa noioso.
E l'IA ha la sua versione dello stesso casino.
Un modello diventa utile, ma nessuno sa davvero chi lo ha reso utile. I dati vengono aggiunti da qualche parte. Un modello viene addestrato. Qualcuno lo ottimizza. Un agente lo usa. Un'app ne trae profitto. Ma sotto il cofano, la traccia è solitamente rotta. Le persone che hanno fornito i dati utili o hanno aiutato a modellare il modello scompaiono nel sistema.
OpenLedger sta cercando di affrontare quel pasticcio.
Non in modo appariscente. Più come la rete idrica.
Il progetto sta fondamentalmente chiedendo: se dati, modelli e agenti IA stanno creando valore, perché il registro di quel valore è così debole? Perché continuiamo a comportarci come se il prodotto finale fosse l'unica cosa che conta? Perché tutti upstream vengono sfocati?
Onestamente, questa è la parte che rende OpenLedger interessante. Non sta solo dicendo “IA più blockchain” e sperando che le parole facciano il lavoro. Si concentra sull'attribuzione. Chi ha contribuito a cosa. Cosa è stato utilizzato. Quale modello dipendeva da quali dati. Quale agente ha creato valore da quali pezzi.
Questo suona noioso finché non hai vissuto abbastanza sistemi di ricompensa crypto che hanno pagato le persone sbagliate.
Allora inizia a sembrare necessario.
Perché la crypto ha una lunga storia di pretese che l'attività equivale a valore. Alto numero di wallet. Alto numero di transazioni. Alta partecipazione sociale. Ma chiunque abbia seguito da vicino una campagna sa quanto di tutto ciò possa essere falso. I bot possono sembrare attivi. I Sybils possono sembrare leali. Le transazioni vuote possono sembrare adozione.
La stessa cosa può accadere nell'IA.
Un dataset può sembrare prezioso ma essere spazzatura. Un modello può sembrare impressionante ma essere assemblato da fonti poco chiare. Un agente può apparire utile mentre nasconde il lavoro che lo alimenta realmente. E una volta che il denaro entra nel sistema, la gente cercherà di sfruttare ogni punto debole.
Ecco perché il focus di OpenLedger su prova, attribuzione e uso è importante.
Non è sexy.
È infrastruttura.
Il punto è che l'IA ha bisogno di un sistema contabile migliore. Non solo per i token. Per il contributo. Se un dataset aiuta un modello a produrre risposte migliori, questo non dovrebbe svanire. Se un modello viene utilizzato all'interno di un agente, quella relazione non dovrebbe essere invisibile. Se un agente crea valore, dovrebbe esserci un modo per tracciare i pezzi dietro di esso.
OpenLedger vuole essere quel livello di registro.
Un libro mastro per le cose sotto il cofano.
Dati. Modelli. Agenti. Uso. Ricompense.
La parte che mi piace è che tratta i dati come qualcosa di vivo, non come un caricamento morto. Nella maggior parte dei sistemi, i dati vengono utilizzati una volta e dimenticati. Qualcuno li estrae, li compra, ci addestra o li nasconde dentro un prodotto. Dopo, il contributore originale non ha alcun reale legame con il valore futuro.
Questo sembra sbagliato.
I buoni dati continuano a funzionare. Continuano a migliorare i risultati. Rendono i modelli più affilati. Allora perché il loro valore dovrebbe finire nel momento in cui entrano nel sistema?
La risposta di OpenLedger è semplice nello spirito: se i dati continuano a creare valore, dovrebbero continuare ad avere un diritto.
Difficile da costruire, però.
Molto difficile.
L'attribuzione nell'IA non è pulita. Un modello non produce una risposta e ti porge gentilmente una ricevuta che mostra quali esatti punti dati contavano. L'influenza è caotica. L'addestramento è caotico. L'ottimizzazione è caotica. Gli agenti sono ancora più caotici perché possono chiamare modelli, strumenti e dataset diversi prima di svolgere un compito.
Quindi no, OpenLedger non sta risolvendo un problema facile.
Ma almeno sta puntando al giusto.
E questo conta perché molti progetti crypto evitano la dura realtà. Inseguono il livello visibile. L'app. Il token. La campagna. La classifica. L'airdrop.
OpenLedger sta guardando più a fondo nella macchina.
Se l'IA sta per diventare un'economia reale, non solo un insieme di API avvolte in belle interfacce, allora ha bisogno di un modo per ricordare da dove proviene il valore. Altrimenti, ripeteremo il solito trauma crypto. I wallet più rumorosi vincono. I veri contribuenti vengono diluiti. Il sistema premia il volume invece dell'utilità.
Abbiamo già visto quel film.
Nessuno ha bisogno di un'altra versione.
L'idea di OpenLedger attorno alle reti di dati ha senso in quel contesto. L'IA specializzata ha bisogno di dati specializzati. Un modello finanziario ha bisogno di dati finanziari. Un modello legale ha bisogno di materiale legale. Un agente di cybersecurity ha bisogno di veri schemi di minaccia, non di testo casuale di internet. La qualità del modello dipende dalla qualità dell'input.
Questo sembra ovvio, ma la maggior parte dei sistemi tratta ancora il livello dei dati come materiale di sfondo.
OpenLedger lo avvicina al centro.
Quello è l'istinto giusto.
Perché il futuro dell'IA probabilmente non è un unico grande modello che fa tutto perfettamente. È più probabile che siano molti modelli focalizzati, tarati per lavori specifici, connessi ad agenti che sanno quando e come usarli. Quel tipo di configurazione ha bisogno di un'infrastruttura pulita. Ha bisogno di registri. Ha bisogno di percorsi di ricompensa. Ha bisogno di un modo per impedire che i contribuenti utili vengano inghiottiti dal prodotto finale.
Di nuovo, la rete idrica.
Non è glamour.
Ma quando la rete idrica si rompe, tutto puzza.
Il token OPEN si inserisce in questo come il layer economico. Viene utilizzato per attività, pagamenti, ricompense, governance e accesso all'interno della rete. Ma non penso che il token sia la cosa più importante su cui concentrarsi prima.
La vera domanda è l'uso.
Porteranno dati preziosi? I costruttori creeranno modelli utili? Gli agenti costruiti su questo verranno effettivamente utilizzati? L'attribuzione sembrerà equa abbastanza che i contribuenti si fidino? Il sistema rifiuterà spam, dati di bassa qualità, partecipazione falsa e tutta la solita spazzatura crypto?
Queste sono le domande che contano.
Un token non può fingere per sempre.
Forse per un po'. Non per sempre.
Guarda, OpenLedger ha un'idea forte, ma l'esecuzione deciderà tutto. Se il sistema di attribuzione è debole, la gente lo sfrutterà. Se la qualità dei dati è scarsa, i modelli ne risentiranno. Se gli strumenti sono troppo complicati, i normali contribuenti non si daranno da fare. Se le ricompense sembrano casuali, i costruttori seri se ne andranno.
Questo potrebbe richiedere tempo.
Probabilmente dovrebbe richiedere tempo.
La buona versione di OpenLedger non è un ciclo di hype veloce. È un'infrastruttura che diventa lentamente utile perché la gente si fida dei registri che mantiene. Si fidano che i contributi non vengano cancellati. Si fidano che l'uso crea ricompense. Si fidano che il sistema stia misurando qualcosa di reale, non solo rumore da wallet.
Questa è la parte che sembra valga la pena osservare.
Perché sotto tutto il linguaggio dell'IA e della blockchain, OpenLedger riguarda davvero la memoria.
La crypto spesso dimentica chi ha realmente aiutato.
L'IA spesso dimentica da dove proviene la sua intelligenza.
OpenLedger sta cercando di costruire qualcosa che non dimentichi così facilmente. Vuole che i dati, i modelli e gli agenti portino con sé la loro storia. Vuole che la catena del valore resti visibile. Vuole che i contribuenti abbiano una possibilità migliore di essere pagati quando il loro lavoro continua a produrre valore.
Questa non è una promessa perfetta.
È una questione difficile.
Ma è il tipo di problema difficile che sembra più utile di un altro cruscotto lucido o di un'altra campagna a punti che finge di misurare la lealtà.
Il pasticcio è reale.
OpenLedger sta cercando di costruire attorno al pasticcio invece di fingere che non ci sia.