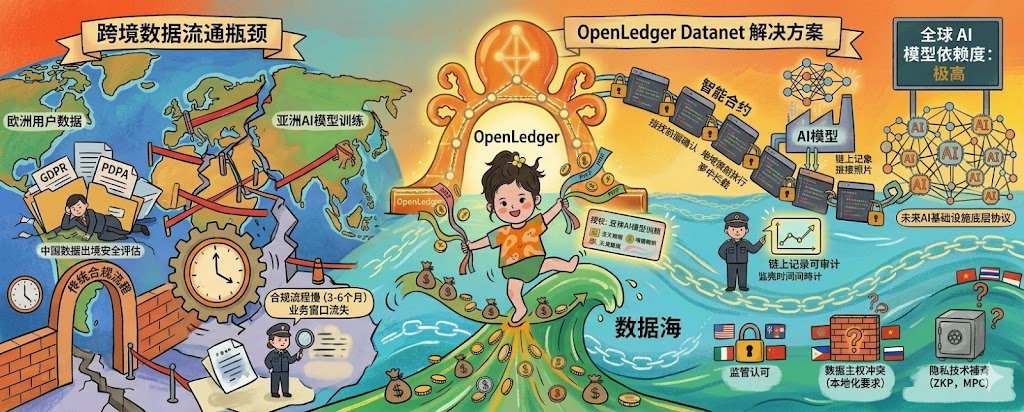
我前段时间跟一个在新加坡做跨境数据合规的朋友吃饭,她吐槽说她们公司今年最头疼的事不是技术,是怎么把欧洲客户的数据合规地用到亚洲的AI模型训练上。GDPR、中国的数据出境安全评估、新加坡的PDPA、印度刚通过的DPDP,每个法域的要求都不一样,很多时候一份数据想跨过一条国境线,光走完合规流程就要三到六个月,等流程走完业务窗口早就过去了。她说现在AI模型迭代得这么快,但数据流通的速度还停留在十年前,这就是整个行业最大的瓶颈。
我那天回家路上一直在想这件事,越想越觉得@OpenLedger 这种链上数据基础设施的价值不只是分润那么简单,它真正可能解决的是跨境数据流通的通行证问题。
为什么这么说?传统的跨境数据流通是怎么走的?大致是这样:A公司想把欧洲用户数据用到亚洲的模型训练上,先要在欧洲做数据脱敏和用户授权确认,然后通过SCCs或者BCRs这种合同框架把数据传到亚洲,亚洲这边接收方再做一次合规审查,整个过程涉及法律、合规、IT、业务四个部门的反复确认,每一步都可能因为某个条款没对齐而卡住。最大的问题是,这套流程没法被监管事后追溯,监管要查这条数据到底有没有合法授权、有没有被用在协议外的场景,基本只能靠企业自己提交的报告。
#OpenLedger 的Datanet在技术设计上恰好绕开了这个传统瓶颈。数据贡献者把数据上传到链上Datanet时,授权范围、使用条件、地域限制都可以写进智能合约,模型训练方调用数据时必须满足合约里写明的条件才能拿到使用权,每一次使用都有链上记录,监管不需要相信企业的报告,直接看链上记录就行。这种设计本质上是把数据通行证从一份纸质合同变成了一段可执行的代码,合规审查从事后追溯变成了事中拦截。
我自己在今年五月这周做了一次小尝试,把手头一些非敏感的代币交易记录贡献到OpenLedger的金融Datanet里,授权条件里我特意限制了只能用于亚洲地区的模型训练。半个月内陆续有几次模型调用涉及到我的数据,我去链上看了一下调用方的钱包活跃区域,确实都是亚洲范围,没有出现违反授权的调用。这件事在Web2平台上根本做不到,传统平台拿走你的数据之后用在哪你完全不知道,OpenLedger至少让我第一次有了我能控制我的数据去哪里的实感。
这套机制如果真的跑通,对跨境AI行业的意义不只是降低合规成本,更重要的是改变了游戏规则。以前小公司想用全球数据训练模型基本没戏,光合规成本就把它们挡在门外,只有大厂养得起几十人的法务团队才能玩这个游戏。OpenLedger这种基础设施一旦成熟,理论上一个三五人的初创团队也能合规地用上多个法域的数据,这对整个AI行业的创新效率会有量级的影响。
不过这套通行证叙事现在还有几道很现实的坎,说清楚比较重要。监管认可是最绕不开的一道,OpenLedger的链上记录在技术层面已经做到了可审计,但各国监管目前还没有明确表态接受区块链凭证作为合规证据,这意味着即使企业用了OpenLedger,过监管这一关时可能还得再走一套传统流程,重复劳动反而增加了成本。数据主权问题也不好处理,中国、俄罗斯、印度都有数据本地化要求,规定关键数据必须存储在境内,OpenLedger的链上数据天然是全球可访问的,这跟数据本地化的要求直接冲突,要解决这个问题要么做分区域的Datanet,要么跟各国监管谈出一套例外条款,两条路都不容易,目前看不到明显的解决方案。还有一点是技术完整度,真正的跨境数据流通需要配合零知识证明、安全多方计算、联邦学习这些隐私技术,$OPEN 目前的Proof of Attribution主要解决的是归属和分润问题,对极度敏感数据的隐私保护强度还不够,这部分能力补齐之前,金融、医疗这些高敏感行业不会真的把核心数据放上来,
OpenLedger能在监管认可、数据主权、隐私技术这三件事上都拿到过得去的答案,OpenLedger就有机会成为下一个时代AI数据基础设施的底层协议之一,那个时候它的价值不会用代币价格来衡量,会用全球有多少AI模型依赖它来衡量。