I’ll be honest I almost ignored the OpenLedger whitepaper at first.
Not because it looked unimportant, but because lately a lot of AI and crypto projects have started to feel strangely repetitive. The same phrases keep coming back again and again: “AI agents,” “decentralized intelligence,” “next-gen inference,” “GPU economy.” After reading enough of these projects, they begin to blend into one another. At some point, it becomes difficult to tell whether you are looking at a genuinely new idea or just the same pitch dressed up in a different way.
But when I actually sat down and read OpenLedger’s thesis carefully, it felt different enough to deserve attention. Not because it was perfect, and not because every part of it felt groundbreaking, but because it seemed to be trying to solve a real problem instead of just chasing a trend.
The main idea is simple, but it stays with you:
AI should remember who helped create it.
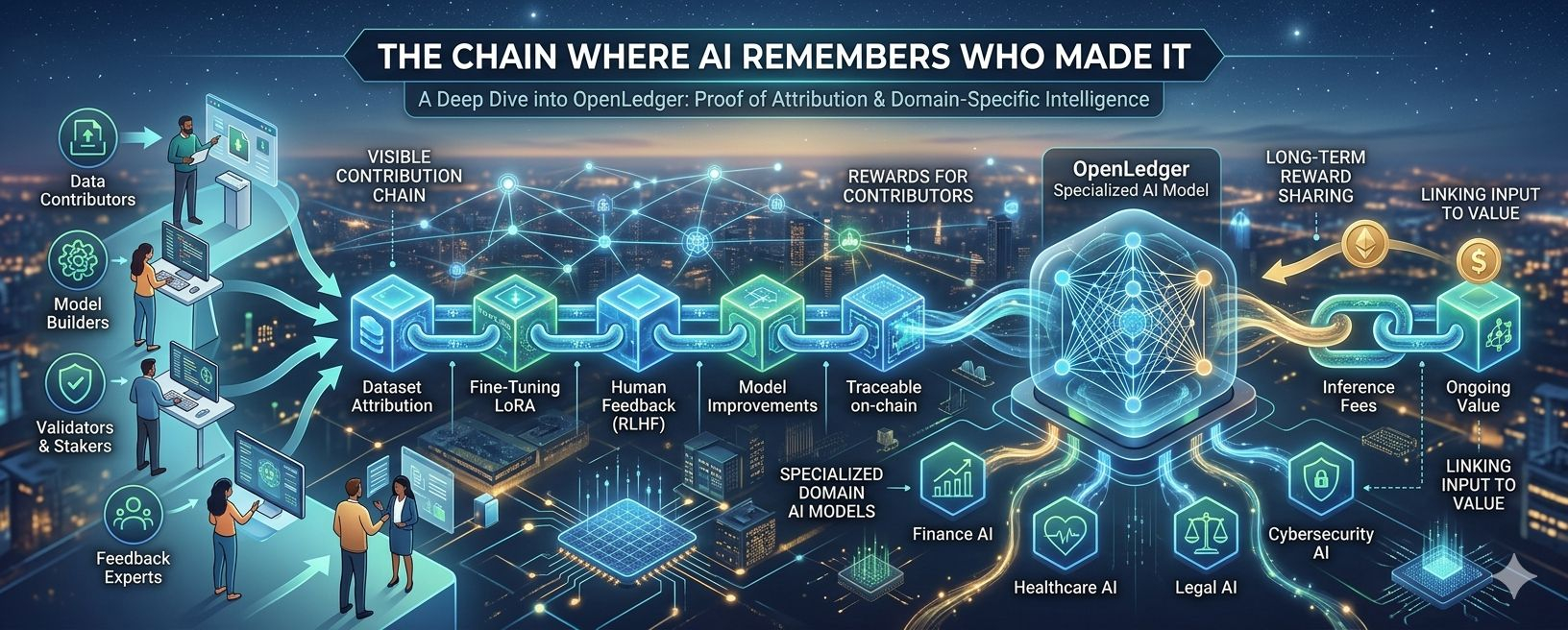
At first, that sounds almost obvious. But the more I thought about it, the more I realized how big that statement really is. Most AI systems today are built from public datasets, human feedback, expert knowledge, community input, and endless small interactions that rarely get recognized in any meaningful way. These inputs help shape the model, improve its responses, and make it more useful over time. Yet when the model becomes valuable, the people behind that improvement usually stay invisible.
That is the problem OpenLedger is trying to address with something it calls Proof of Attribution.
Instead of treating AI like a closed black box, OpenLedger wants the contribution chain to be visible. The idea is that datasets, fine-tuning, validator feedback, and model improvements should all be traceable on-chain. If that works properly, then people who actually helped shape the intelligence behind the model would have a chance to be rewarded for it later.
And honestly, that is one of the few AI + blockchain ideas I have seen recently that did not feel completely artificial.
What I also appreciated is that OpenLedger does not come across like one of those projects that claims it will replace OpenAI or somehow become the next GPT killer. That kind of promise usually makes me skeptical right away. OpenLedger feels more measured than that. Its focus seems to be on specialized AI rather than one giant model trying to do everything.
That approach makes sense to me.
Instead of pushing a single all-purpose system, the idea is to build domain-specific AI models for areas like finance, healthcare, cybersecurity, and legal research. In real-world use, that often feels far more practical. Smaller models that are trained on high-quality domain data can sometimes be more useful than massive general models that try to cover every possible task.
The economic side is where the thesis becomes even more interesting.
OpenLedger wants to create a setup where, if an AI model generates inference fees or produces ongoing value, the rewards can be shared among the people who contributed to that model. That could include model builders, data contributors, validators, and stakers. In simple terms, if your dataset genuinely helped improve the model, you would not just disappear after uploading it. You could theoretically continue to benefit from the value that contribution helped create.
That is a pretty serious shift from how the AI economy works today.
Right now, most people who contribute data, feedback, or intelligence to AI systems do not really participate in the long-term upside. Their input helps make the model better, but the value often gets captured elsewhere. OpenLedger is trying to challenge that pattern by linking contribution and reward more directly.
The technical part of the paper also felt more grounded than I expected.
It discusses things like LoRA fine-tuning, RLHF, influence functions, RAG attribution, GPU scheduling, and multi-tenant model serving. That matters because it suggests the project is not just throwing AI buzzwords into a token narrative. It seems to have spent time thinking about how modern AI infrastructure actually works.
Still, none of that removes the hard part.
Attribution inside large AI systems is extremely difficult. That is not a small issue, and it is not something that can be solved by good marketing. Figuring out which exact dataset influenced a model response at scale is still a very open research problem. So even if the idea is attractive, execution will matter much more than the framing.
That is the part I would watch most closely.
Even then, I think OpenLedger understands something that a lot of AI crypto projects miss completely.
The future of AI will probably not be only about model size or raw capability. It will also be about ownership, attribution, provenance, and how value flows through the system. In other words, the next big question may not just be what AI can do, but who actually made that intelligence possible in the first place.
And to me, that feels like a much more serious conversation than another random “AI agent coin” story.