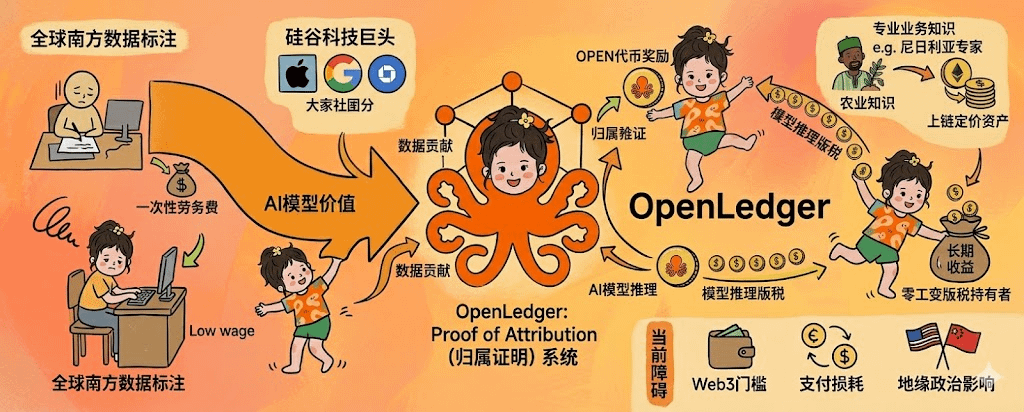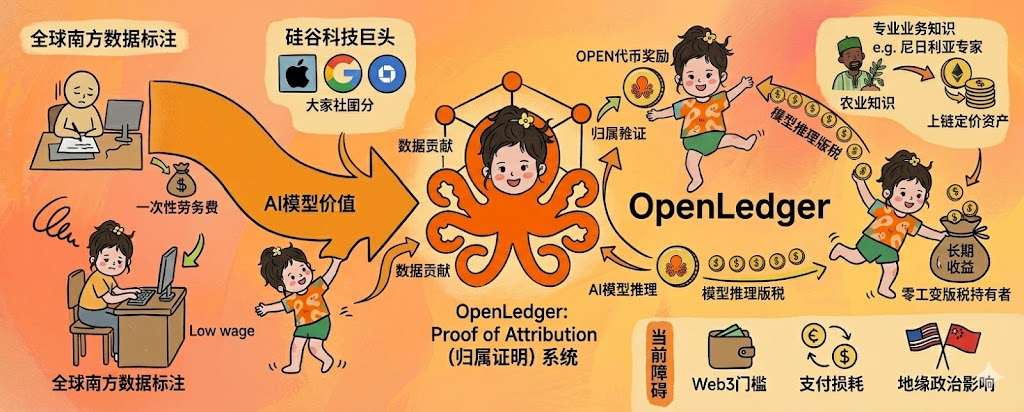
我有个肯尼亚的网友,前两年在内罗毕一家做数据标注的外包公司上班,每小时工资差不多1.5到2美元,主要工作是给社交平台的内容审核模型标注数据,每天看几百条违禁内容把它们打上标签。她跟我说过最讽刺的一件事,她标的数据被拿去训练AI模型,那个模型后来值几十亿美元,她每个月拿到手的还是那点工资,连一台像样的电脑都买不起。这种数据来自全球南方,价值流向硅谷的不对等关系,是过去十年AI产业最隐蔽的一种系统性剥削,@OpenLedger 的Proof of Attribution机制如果能落地,理论上可以从根本上改写这件事。
把这件事说清楚需要先理解全球AI数据产业的真实分工。绝大部分数据标注、内容审核、模型微调的真实劳动都发生在肯尼亚、印度、菲律宾、巴基斯坦这些国家,本地工人时薪普遍在1到3美元区间。这些数据被打包卖给OpenAI、Google、Meta这种总部在美国的AI公司,模型训练完上线之后产生的商业价值动辄百亿美元级别,但回流到原始数据贡献者手里的部分接近于零。Brookings和LSE在2025年的研究都指出,全球南方数据工人正面临训练完AI模型之后被AI模型替代的双重困境,他们既贡献了底层数据又拿不到任何长期收益。
#OpenLedger 的差异化做法是把贡献的结算从一次性的劳务报酬变成了长期的版税分成。这是一个机制层面的根本变化。传统外包模式下,肯尼亚数据标注员标完一批数据拿到一次性工资就完事,模型后续被调用一万次还是一百亿次跟她没有任何关系。Proof of Attribution系统改变的是这种关系,每次模型推理时只要识别出这次输出受了某条原始数据的影响,对应的贡献者就能自动收到OPEN代币奖励。这种机制如果能落地,相当于把肯尼亚数据工人从零工变成了内容版税持有者,跟YouTube给视频创作者分成的模式同构。
我自己跟那个肯尼亚网友聊过这件事,她的反应很现实,她不在乎技术原理,她在乎的是我标一条数据能拿多少钱,多久到账,能不能换成本地货币。这三个问题OpenLedger目前的答案都还不够清晰。$OPEN 代币需要先在交易所卖出换成稳定币,再通过P2P渠道兑换成肯尼亚先令,每一步都有汇率损失和手续费,对于一个时薪1.5美元的工人来说,几个百分点的损耗就是真金白银的影响。
OpenLedger这套机制对全球南方还有一个更深层的意义,是它把专业知识变成了可以上链定价的资产。一个尼日利亚的农业专家如果把当地作物种植数据上传到Datanet,被全球范围内的农业AI模型用来做病虫害识别,那他获得的回报理论上可以远超在本地做农技顾问的收入。这种知识无国界但收益可量化的模式,在过去几乎不可能存在,因为中心化AI公司没有机制也没有动机去给原始知识贡献者付费。区块链attribution打开了这个可能性,但能不能真正让全球南方的专业知识工作者拿到匹配的回报,要看采用率能不能在未来三五年里上一个量级。
但这套叙事面对的现实障碍也得说清楚。技术门槛是第一道坎,OpenLedger的Datanet和Model Factory目前对普通用户来说仍然不够友好,全球南方的大多数潜在贡献者还在用低端智能机,连接Web3钱包这件事本身就能拦住一大批人,更别说后续的数据上传和attribution设置了。网络效应是另一个等待期的问题,attribution的价值要随着调用量上来才能显现,主网刚上线不到两周,早期贡献者拿到的代币奖励额度有限,对于追求即时收入的低收入工人来说这种长期主义很难撑下去。地缘政治也是个绕不开的变量,美国对中国AI的出口管制可能间接影响全球南方对去中心化AI基础设施的接入路径,OpenLedger作为一个开放协议看起来中立,但它的代币和技术栈最终会卷入大国博弈,这不是项目方能控制的。
我觉得全球南方与数字包容性这条叙事是OpenLedger所有故事里最有道德重量的一条,它不只是商业模式创新,而是真正在尝试解决一个被掩盖了十年的不公平。如果这套机制能在未来五年内让肯尼亚、印度、菲律宾的数据工人多拿到哪怕10%的长期分成,那它对全球数字劳动公平的推动就远超大部分慈善项目。但理想跟落地之间隔着技术门槛、支付通道、网络效应、地缘政治这一连串硬骨头,OpenLedger现在做的是开了第一道口子,能不能撑到把全球南方拿到AI价值链合理分成这件事变成现实,要再看十年。