C'è un numero a cui continuo a tornare. Microsoft ha pagato 10 miliardi per investire in OpenAI. Google ha investito miliardi in Gemini. Meta ha speso più del PIL di molte nazioni per costruire la propria infrastruttura di IA.
Da dove è venuto tutto quel valore? Non dai ricercatori in camici da laboratorio. Non dai server che ronzano in strutture con clima controllato. Non nemmeno dagli algoritmi stessi.
È venuto dai dati. Oceani di dati. Generati da persone comuni che vivono vite comuni su internet. Persone che non avevano assolutamente idea che le loro parole, le loro immagini, i loro modelli di comportamento venivano silenziosamente trasformati nella risorsa più preziosa del 21° secolo. Hai finanziato la rivoluzione dell'IA.
Non hai mai ricevuto una fattura — o un assegno.
La Matematica Scomoda
Lascia che lo metta in termini difficili da ignorare. GPT-4 è stato addestrato su circa 45 terabyte di dati testuali. Il dataset di Common Crawl da solo — un'enorme estrazione di contenuti web disponibili pubblicamente — contiene miliardi di documenti scritti da veri esseri umani nel corso di decenni. Thread di Reddit. Risposte su Stack Overflow. Modifiche a Wikipedia. Post di blog. Discussioni nei forum.
Persone reali. Pensiero reale. Lavoro reale.
Ora guarda la valutazione di OpenAI. Guarda quanto costa una singola chiamata API. Guarda quanto fatturano questi modelli ogni singolo mese.
Poi guarda cosa hanno ricevuto le persone che hanno creato i dati sottostanti.
La matematica non è complicata. La conclusione è solo scomoda per le persone che beneficiano dell'attuale accordo.
Perché l'Attribuzione Non È Mai stata Costruita
Ho pensato a questo a lungo e continuo a arrivare alla stessa risposta. L'attribuzione non è stata integrata nei sistemi di IA fin dall'inizio perché non era nell'interesse di nessuno costruirla.
I data scrapers beneficiano dell'ambiguità. Le aziende di IA beneficiano dell'ambiguità. Gli investitori beneficiano dell'ambiguità. L'intero modello economico attuale dell'IA è costruito sull'assunzione silenziosa che i dati siano una risorsa naturale gratuita piuttosto che qualcosa creato da persone che meritano riconoscimento e compenso.
Cambiare quell'assunzione non richiede solo buone intenzioni. Richiede un'infrastruttura che renda impossibile nascondere il vecchio modo di fare.
È una cosa più difficile da costruire rispetto a un chatbot. Ma è la cosa che conta davvero.
Cosa Cambia la Prova di Attribuzione
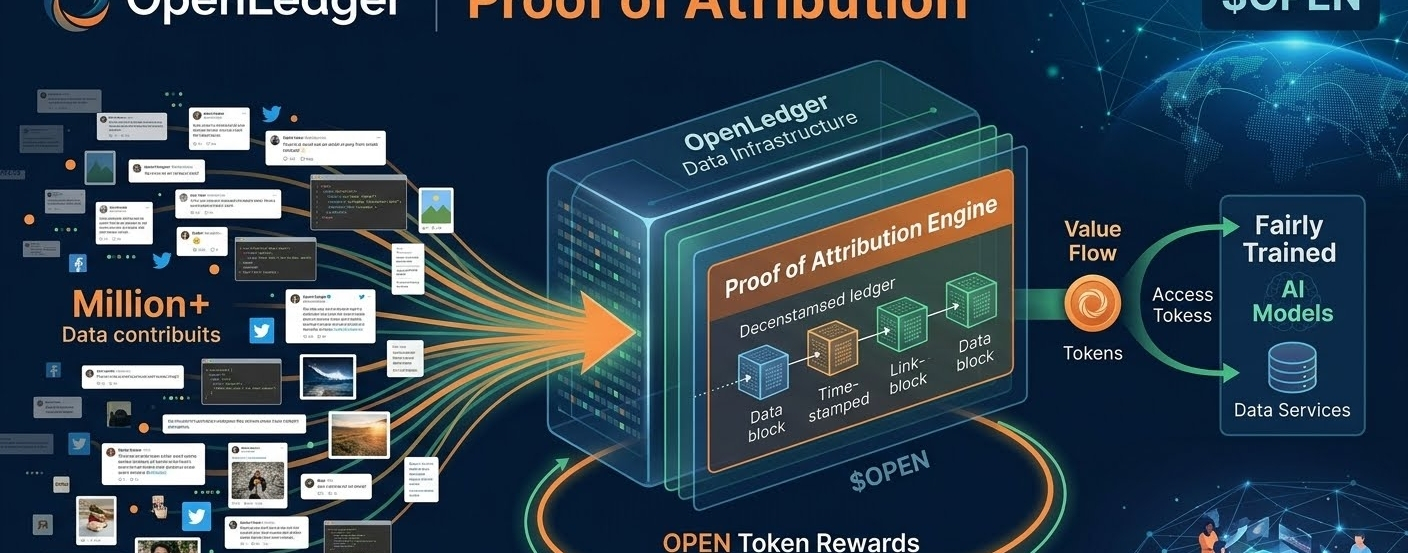
La Prova di Attribuzione di OpenLedger non è solo una funzionalità. È un riformulazione fondamentale del rapporto tra i creatori di dati e i sistemi di IA.
Quando il tuo contributo è registrato on-chain, qualcosa cambia. Non sei più una fonte anonima. Sei un partecipante verificabile. Il tuo input ha un timestamp, un record, un percorso tracciabile attraverso il sistema. E criticamente, quel record crea la base per una compensazione che non richiede di fidarsi di nessuno.
Il token OPEN non è solo un asset speculativo seduto su un exchange. È il meccanismo attraverso il quale un'economia dei dati più equa funziona effettivamente. I contributi fluiscono, l'attribuzione viene registrata, il valore fluisce di nuovo verso le persone che l'hanno creato.
Quella loop — chiuso, trasparente, automatico — è qualcosa che l'industria dell'IA non ha mai avuto prima. Non perché fosse tecnicamente impossibile. Ma perché era economicamente scomodo per tutti coloro che contano fino ad ora.
L'Economia dei Creatori È Sempre stata Incompleta
C'è una conversazione parallela in corso nello spazio dell'economia dei creatori che penso si colleghi direttamente a ciò che OpenLedger sta facendo.
Piattaforme come YouTube, Instagram e Spotify hanno costruito interi modelli di business attorno all'idea di compensare i creatori per i loro contributi. L'esecuzione è stata imperfetta — spesso profondamente ingiusta — ma il principio ha stabilito qualcosa di importante. Che le persone che generano valore meritano una parte di quel valore.
L'IA in qualche modo ha completamente perso quel memo. O, più precisamente, è arrivata alla festa dopo che il memo era stato scritto e lo ha messo silenziosamente nel cestino.
OpenLedger sta essenzialmente estendendo il principio dell'economia dei creatori nello strato di addestramento dell'IA. Il luogo in cui il valore viene effettivamente creato, non solo visualizzato. E lo sta facendo con un'infrastruttura che non dipende dalla buona volontà di una piattaforma o da una chiamata agli utili trimestrali per continuare a funzionare.
Il Cambiamento È Già in Corso
Ciò che mi dà vera fiducia in dove stiamo andando non è solo la tecnologia o la tokenomics. È la direzione del mondo che ci circonda.
I creatori stanno facendo causa. I regolatori stanno intervenendo. I tribunali stanno stabilendo precedenti. La consapevolezza pubblica riguardo alle pratiche sui dati dell'IA è ai massimi storici e continua a crescere.
La finestra in cui le aziende di IA potevano costruire silenziosamente su dati non attribuiti e non affrontare conseguenze si sta chiudendo. Forse non domani. Forse non quest'anno. Ma si sta chiudendo e tutti quelli che prestano attenzione lo sanno.
Quando quella finestra si chiude completamente, l'infrastruttura per un'economia dell'IA trasparente e attribuita non sarà più una bella idea. Sarà una necessità.
OpenLedger sta costruendo quell'infrastruttura proprio ora, mentre la maggior parte delle persone sta ancora discutendo se il problema è reale.
Cosa So per Certo
Non so esattamente dove scambierà il token OPEN tra dodici mesi. Nessuno lo sa e chiunque ti dica diversamente sta indovinando con una fiducia che non ha guadagnato.
Quello che so è che il problema che OpenLedger sta risolvendo è reale, urgente e in crescita. Che le persone che l'hanno costruito comprendono sia la tecnologia che il momento in cui operano. E che l'alternativa — un'economia dell'IA che continua a estrarre valore dai creatori senza alcuna responsabilità — sta diventando sempre più difficile da sostenere legalmente, politicamente e pubblicamente con il passare dei mesi.
I tuoi dati sono sempre stati un valore.
OpenLedger sta finalmente costruendo il sistema che lo dimostra.
\u003cc-82/\u003e \u003ct-84/\u003e \u003cm-86/\u003e