Per molto tempo, progetti come OpenLedger sono esistiti nel rumore di fondo dell'industria cripto, circolando principalmente tra sviluppatori, ricercatori di infrastrutture e investitori che trascorrono il loro tempo a guardare diversi anni avanti anziché inseguire l'ultimo ciclo di mercato. Non era il tipo di progetto che dominava i forum di trading al dettaglio o generava un'immediata eccitazione mainstream. In molti modi, quella quiete era parte del suo fascino. Le persone che prestavano attenzione a OpenLedger non stavano necessariamente cercando un'altra meme coin o un altro esperimento di finanza decentralizzata di breve durata. Stavano cercando di capire se l'intelligenza artificiale stesse iniziando a creare un problema di infrastruttura completamente nuovo che i sistemi esistenti erano mal equipaggiati per gestire.
Quella domanda conta molto di più ora di quanto non facesse anche solo dodici mesi fa. L'intelligenza artificiale non è più trattata come un settore sperimentale a margine dell'industria tecnologica. I governi ora discutono dell'infrastruttura AI con la stessa serietà una volta riservata alla sicurezza energetica o alle reti di telecomunicazione. Grandi corporations stanno riorganizzando i budget attorno ai sistemi di machine learning. I fornitori di cloud stanno correndo per costruire cluster di calcolo più grandi. Le aziende di semiconduttori stanno vedendo una domanda straordinaria per hardware in grado di gestire i carichi di lavoro AI. Allo stesso tempo, l'economia che circonda questi sistemi rimane sorprendentemente concentrata. Un numero relativamente ridotto di aziende controlla i modelli, l'infrastruttura, le pipeline di dati e, sempre di più, il valore commerciale generato da essi.
Questa concentrazione ha creato un crescente senso di inquietudine all'interno di parti dell'industria tecnologica. Gli sviluppatori si preoccupano della dipendenza da sistemi chiusi. I ricercatori si preoccupano della trasparenza. I fornitori di dati si preoccupano del compenso. I regolatori si preoccupano della responsabilità. OpenLedger sta cercando di posizionarsi direttamente all'interno di quelle tensioni proponendo uno strato di coordinamento decentralizzato per l'intelligenza artificiale stessa.
A prima vista, l'idea sembra quasi astratta. Il progetto si descrive come un'infrastruttura per quello che chiama 'AI Pagabile', un sistema in cui le persone o le organizzazioni che contribuiscono agli ecosistemi AI possono essere identificate, verificate e compensate automaticamente attraverso un'architettura basata su blockchain. Il linguaggio assomiglia a una miscela di computing distribuito, finanza decentralizzata ed economia del machine learning. Questa combinazione naturalmente attrae scetticismo perché l'industria crypto ha trascorso anni ad associare la terminologia blockchain a settori di moda senza sempre produrre sistemi che sopportano lo stress del mondo reale.
Eppure, sotto il linguaggio di marketing si nasconde una seria domanda di fondo. L'intelligenza artificiale sta diventando sempre più dipendente da enormi reti di input distribuiti, eppure la struttura economica attorno a quegli input rimane notevolmente primitiva. La maggior parte dei modelli AI oggi funziona come enormi motori di estrazione centralizzati. I dati entrano nel sistema da innumerevoli fonti esterne, vengono assorbiti in modelli proprietari e producono infine output commerciali controllati da un piccolo numero di aziende. Le persone il cui lavoro, contenuto, conoscenza o risorse computazionali hanno contribuito a plasmare quei sistemi raramente mantengono visibilità una volta che il processo inizia.
OpenLedger sembra essere costruito attorno all'assunzione che questa struttura possa eventualmente diventare instabile.
Per capire perché il progetto esista, è utile guardare attentamente a come i moderni sistemi AI sono effettivamente assemblati. La discussione pubblica attorno all'intelligenza artificiale crea spesso l'impressione che i modelli emergano completamente formati dal dipartimento ingegneristico di un'unica azienda. La realtà è più vicina a una rete industriale globale. L'addestramento di modelli avanzati richiede enormi set di dati raccolti da archivi pubblici di internet, articoli di ricerca, database di immagini, video, interazioni degli utenti, sistemi informativi aziendali e innumerevoli altre fonti. Questi sistemi si basano su un'enorme infrastruttura computazionale distribuita tra fornitori di hardware specializzati e reti cloud. Dipendono da sistemi di etichettatura, pipeline di apprendimento per rinforzo, strati di ottimizzazione del modello e meccanismi di feedback continuo.
Ogni passo di quel processo crea valore economico per qualcuno, ma la distribuzione di quel valore è altamente disuguale.
Un ricercatore potrebbe contribuire con dati di addestramento altamente specializzati che alla fine migliorano un modello AI commerciale del valore di miliardi di dollari. Un sviluppatore può creare strumenti di infrastruttura utilizzati in sistemi di machine learning su larga scala senza mantenere una partecipazione a lungo termine nell'upside economico generato da essi. I fornitori di dati indipendenti spesso perdono visibilità una volta che le loro informazioni entrano in architetture di addestramento centralizzate. Anche le aziende che implementano l'AI internamente faticano frequentemente ad auditare come vengono generati gli output o quali fonti hanno influenzato il comportamento del sistema.
Questo crea problemi pratici che si estendono oltre l'ideologia.
Il primo problema è l'attribuzione. Le dispute sul copyright riguardanti i dati di addestramento dell'AI stanno già aumentando a livello globale. Editori, artisti, scrittori e sviluppatori software si stanno chiedendo se i modelli addestrati sul loro lavoro dovrebbero produrre output commerciali senza compenso. I sistemi legali esistenti non sono stati progettati per architetture di machine learning probabilistiche che assorbono frammenti di milioni di input separati simultaneamente. Determinare la proprietà all'interno di quegli ambienti diventa estremamente difficile.
Il secondo problema è la coordinazione. Lo sviluppo dell'AI dipende sempre più da risorse distribuite globalmente, ma i sistemi che gestiscono quelle risorse rimangono frammentati e pesantemente centralizzati. I piccoli sviluppatori faticano ad accedere all'infrastruttura computazionale. I contributori indipendenti mancano di meccanismi standardizzati per monetizzare set di dati specializzati. Le imprese esitano a condividere informazioni senza garanzie chiare riguardo alla proprietà e ai diritti d'uso.
Il terzo problema è la fiducia. Man mano che l'intelligenza artificiale si integra all'interno di finanza, logistica, sanità, robotica, manifattura e sistemi governativi, le organizzazioni hanno bisogno di modi per verificare da dove provengono i modelli, quali dati li hanno plasmati e se gli output possono essere auditati dopo il deployment. I sistemi a scatola nera diventano molto più difficili da difendere quando la responsabilità del mondo reale entra in gioco.
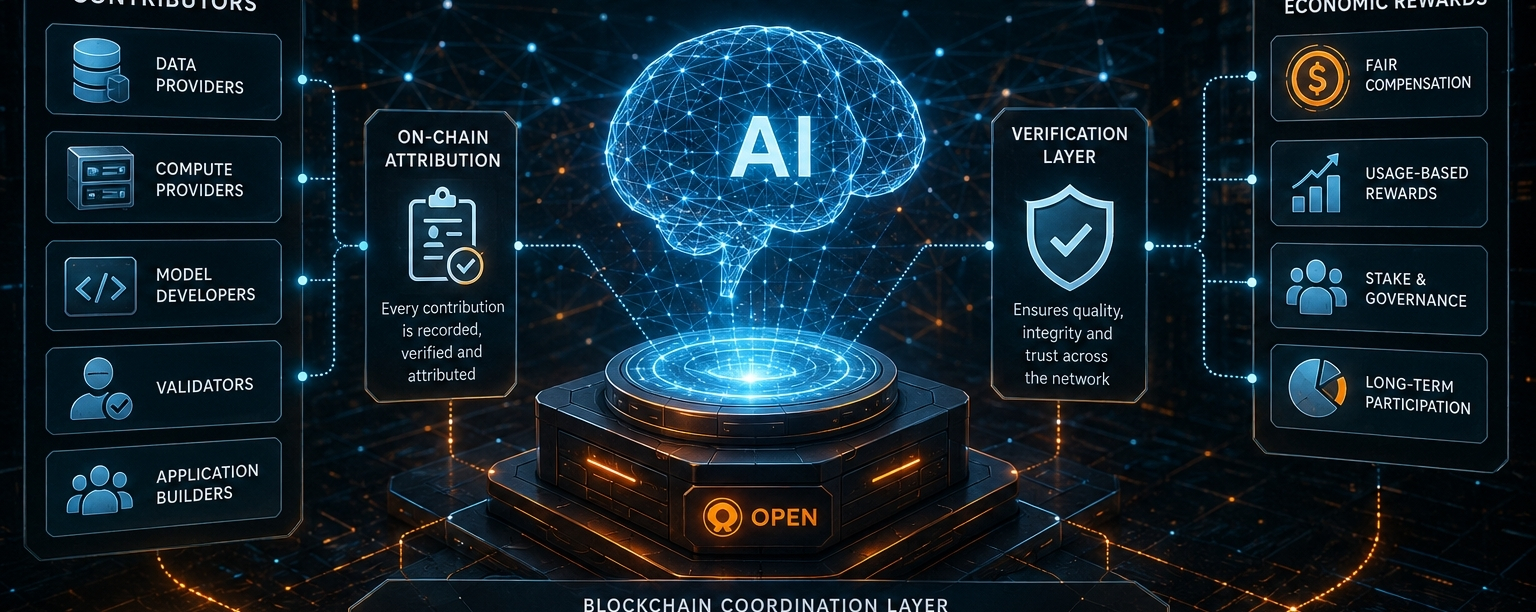
OpenLedger sta cercando di affrontare questi problemi creando uno strato di coordinamento basato su blockchain dove i contributi ai sistemi AI possono essere registrati, verificati e premiati economicamente.
Ciò che molti osservatori casuali non vedono è che il progetto non sta realmente tentando di competere direttamente con le aziende che costruiscono modelli AI all'avanguardia. Sta tentando di costruire un'infrastruttura economica sotto di loro. Questa distinzione cambia il modo in cui il progetto dovrebbe essere compreso.
La maggior parte delle aziende AI oggi opera attraverso modelli verticalmente integrati. Controllano i set di dati, l'infrastruttura di calcolo, le pipeline di addestramento e le applicazioni commerciali internamente. OpenLedger sta effettivamente scommettendo che l'economia AI a lungo termine potrebbe evolversi in qualcosa di più modulare e distribuito, dove i contributori indipendenti forniscono diversi strati di valore attraverso una rete condivisa piuttosto che all'interno di ecosistemi aziendali chiusi.

In quel mondo, un contributore potrebbe fornire un set di dati specializzato per la salute mentre un altro partecipante fornisce risorse computazionali per l'addestramento. Un terzo gruppo potrebbe operare sistemi di validazione che verificano la qualità degli output. Gli sviluppatori potrebbero quindi costruire applicazioni sopra quei modelli mentre le ricompense economiche fluiscono automaticamente tra i partecipanti in base all'attività e all'uso della rete.
Questo inizia a somigliare a un sistema operativo economico per l'intelligenza artificiale piuttosto che semplicemente a un'altra applicazione blockchain.
L'architettura dietro il progetto riflette quella ambizione. Lo strato blockchain funge da spina dorsale di coordinamento dove i contributi, le interazioni e le tracce di proprietà vengono registrati. I sistemi di identità stabiliscono reputazioni persistenti per i contributori, il che diventa essenziale perché i sistemi decentralizzati non possono funzionare senza meccanismi per valutare la fiducia. Gli strati di verifica cercano di garantire che i contributi di dati, le affermazioni computazionali o gli output del modello soddisfino standard predefiniti piuttosto che inondare la rete con manipolazioni e input di bassa qualità.
I meccanismi di regolamento distribuiscono quindi ricompense economiche attraverso il token OPEN, che funge da infrastruttura contabile all'interno dell'ecosistema.
Concettualmente, il sistema prende in prestito pesantemente da finanza decentralizzata, cloud computing distribuito e coordinamento software open-source. Ma combinare quei concetti introduce enormi complessità. Ogni strato crea sfide operative che diventano sempre più difficili su scala.
I sistemi di attribuzione richiedono un sovraccarico computazionale. I sistemi di verifica diventano vulnerabili alla manipolazione. I meccanismi di governance creano dispute su come il valore dovrebbe essere misurato e distribuito. Una volta che compaiono incentivi finanziari, i partecipanti iniziano a ottimizzare il comportamento attorno all'estrazione piuttosto che all'integrità a lungo termine della rete. Questo schema è apparso ripetutamente attraverso gli ecosistemi crypto nell'ultimo decennio.
Quella storia è importante perché molti sistemi decentralizzati funzionano bene durante le fasi di crescita iniziale ma diventano instabili una volta che arrivano incentivazioni economiche significative. I programmi di mining di liquidità hanno attratto utenti temporaneamente ma raramente hanno costruito lealtà sostenibile. Gli ecosistemi di gioco play-to-earn hanno generato attività fino a quando le strutture di ricompensa sono diventate economicamente insostenibili. I sistemi di token sociali spesso sono collassati nella speculazione scollegata dalla reale utilità.
OpenLedger sta cercando di evitare quelle trappole legando gli incentivi direttamente ai contributi produttivi di AI piuttosto che a un'attività puramente finanziaria. Se quel modello rimarrà stabile in condizioni reali è ancora incerto.
Il token OPEN stesso si trova al centro di questa struttura di coordinamento. In teoria, svolge diversi ruoli simultaneamente. Funziona come infrastruttura di pagamento per le transazioni all'interno della rete, partecipazione alla governance per le decisioni sui protocolli, collaterale di staking per i sistemi di verifica e distribuzione degli incentivi per i contributori che forniscono set di dati, risorse di calcolo o servizi di validazione.
Questo tipo di architettura di token multi-ruolo è diventata comune tra i progetti di infrastruttura blockchain perché consente ai sistemi decentralizzati di coordinare i partecipanti senza fare affidamento su strutture di proprietà centralizzate. Il token diventa effettivamente sia il motore economico che il meccanismo di enforcement all'interno della rete.
Ma i sistemi di token spesso lottano con una contraddizione di base. L'utilità teorica e il comportamento di mercato raramente si allineano in modo pulito.
Se la speculazione domina l'attività della rete, il prezzo del token diventa scollegato dall'uso produttivo. I contributori si concentrano sull'estrazione a breve termine piuttosto che sullo sviluppo dell'infrastruttura. I sistemi di governance tendono a concentrarsi tra i grandi detentori. La volatilità economica scoraggia l'adozione da parte delle imprese perché le aziende generalmente evitano di costruire infrastrutture critiche attorno a beni finanziari altamente instabili.
OpenLedger quindi affronta una sfida comune a molti progetti di infrastruttura blockchain. Deve evolversi da un ecosistema di asset speculativi in qualcosa in cui le imprese realmente si fidano come infrastruttura operativa.
Quella transizione è straordinariamente difficile.
Ciò che rende il progetto davvero interessante è il suo focus sull'attribuzione come una caratteristica architettonica nativa piuttosto che un processo contabile esterno. La maggior parte dei sistemi AI oggi considera il tracciamento dei contributi come secondario rispetto alle performance del modello. OpenLedger cerca di incorporare l'attribuzione direttamente nello strato di coordinamento stesso.
Se questo approccio funziona, potrebbe creare modelli economici completamente nuovi attorno all'intelligenza artificiale.
Immagina sistemi robotici addestrati su dati operativi forniti dai produttori a livello globale. Immagina sistemi di diagnostica medica costruiti da set di dati forniti da ospedali, laboratori e ricercatori in diverse giurisdizioni. L'infrastruttura di attribuzione potrebbe teoricamente consentire ai contributori di mantenere una partecipazione economica continua nel valore generato da quei sistemi nel tempo.
Questo è dove OpenLedger inizia a muoversi oltre le narrazioni crypto convenzionali.
Il progetto inizia a somigliare a un'infrastruttura per mercati del lavoro digitali costruiti attorno all'intelligenza artificiale stessa. La blockchain non è il prodotto. È il meccanismo di contabilità e coordinamento che consente relazioni economiche tra i partecipanti distribuiti dell'AI.
Eppure, gli ostacoli che affrontano questa visione rimangono sostanziali.
Il problema più difficile non è l'innovazione tecnologica. È il comportamento umano.
I sistemi aperti diventano estremamente difficili da gestire una volta che emergono incentivi finanziari reali. I partecipanti cercano di manipolare i sistemi di reputazione. Dati di bassa qualità inondano le reti se le strutture di ricompensa sono male calibrate. Le dispute di governance si intensificano attorno alle metriche di valutazione. Gli strati di verifica richiedono un'adattamento costante per prevenire sfruttamenti.
Allo stesso tempo, l'industria AI più ampia si sta dirigendo verso una crescente centralizzazione piuttosto che decentralizzazione. I requisiti computazionali per addestrare modelli all'avanguardia continuano a salire drasticamente. I grandi fornitori di cloud possiedono enormi economie di scala attorno al deployment dell'infrastruttura. I governi trattano sempre più le capacità avanzate di AI come tecnologie strategicamente sensibili legate a preoccupazioni di sicurezza nazionale.
Quell'ambiente favorisce naturalmente grandi operatori centralizzati.
OpenLedger quindi occupa una posizione insolita. Sta cercando di costruire infrastruttura decentralizzata in un periodo in cui sia gli incentivi economici che le pressioni geopolitiche stanno spingendo l'intelligenza artificiale verso la concentrazione.
La regolamentazione aggiunge un ulteriore strato di incertezza. I quadri di governance AI rimangono instabili a livello globale. Le dispute sul copyright riguardanti i dati di addestramento continuano ad espandersi. I sistemi blockchain affrontano controlli continui riguardo alla classificazione dei token, alla conformità finanziaria e alle regole operative transfrontaliere. OpenLedger esiste all'incrocio di entrambi gli ambienti normativi contemporaneamente, il che crea complessità legale che si estende ben oltre i normali progetti crypto.
Eppure, nonostante quelle sfide, il progetto continua ad attrarre attenzione perché affronta una domanda che l'industria tecnologica non ha risolto in modo chiaro. Se l'intelligenza artificiale diventa un'infrastruttura fondamentale per l'economia globale, chi partecipa economicamente nei sistemi che la rendono possibile?
In questo momento, la risposta è relativamente semplice. Principalmente grandi corporations e fornitori di infrastrutture.
OpenLedger sta cercando di proporre una struttura alternativa in cui il contributo stesso diventa economicamente visibile e l'intelligenza artificiale opera attraverso una coordinazione distribuita piuttosto che attraverso silo di proprietà chiusi. Se quella visione avrà successo dipende molto meno dalla speculazione sui token e molto di più dal fatto che organizzazioni reali decidano che l'infrastruttura risolve problemi operativi pratici meglio dei sistemi centralizzati già dominanti nel mercato.
È lì che il futuro di progetti come OpenLedger sarà effettivamente deciso. Non sulle exchange crypto. Non all'interno delle narrazioni dei social media. Ma all'interno del processo molto più lento e meno glamour di convincere imprese, sviluppatori e istituzioni che la coordinazione decentralizzata può funzionare in modo affidabile in condizioni del mondo reale dove responsabilità, performance e sostenibilità economica contano più dell'ideologia.