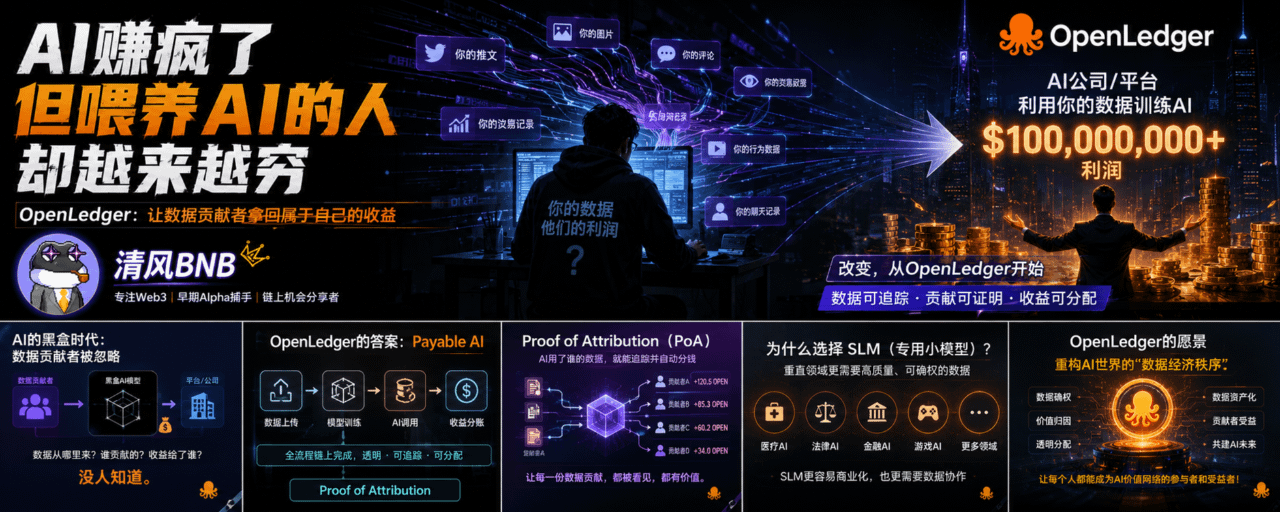

L'AI sta facendo impazzire i guadagni, ma chi nutre l'AI diventa sempre più povero, mentre quelli che shortano BTC e ETH stanno guadagnando.
Ultimamente ho la sensazione sempre più forte che ci sia una cosa:
l'AI sta cambiando il mondo.
Ma le persone comuni potrebbero diventare il 'carburante' più economico dell'era dell'AI.
I tweet, le immagini, i record di trading, i commenti, i contenuti delle chat che pubblichi ogni giorno, persino quei pochi secondi in cui fermi i video, vengono silenziosamente registrati dalle piattaforme.
Dove vanno a finire tutti questi dati?
Con alta probabilità: entrano nei modelli AI.
Poi vengono addestrati nuovi prodotti AI, che vengono venduti dalle grandi aziende in tutto il mondo per fare profitti.
La cosa più ridicola è:
Le persone che contribuiscono realmente ai dati praticamente non ricevono alcun profitto.
In parole povere, il problema centrale dell'industria AI non è nemmeno se il modello sia abbastanza potente.
ma è:
“Chi possiede il valore creato dai dati?”
Non avevo mai pensato seriamente a questa questione prima.
Solo recentemente, studiando OpenLedger, ho scoperto:
Già qualcuno ha iniziato a cercare di ricostruire le “relazioni di produzione” nel mondo AI.
Molti quando vedono OpenLedger per la prima volta, pensano che sia solo un altro:
“AI + blockchain”
Progetti.
Ma più guardo, più credo che ciò che vuole risolvere sia un problema molto fondamentale nell'industria AI:
Chi ha usato i dati di AI?
E:
Queste persone dovrebbero guadagnare?
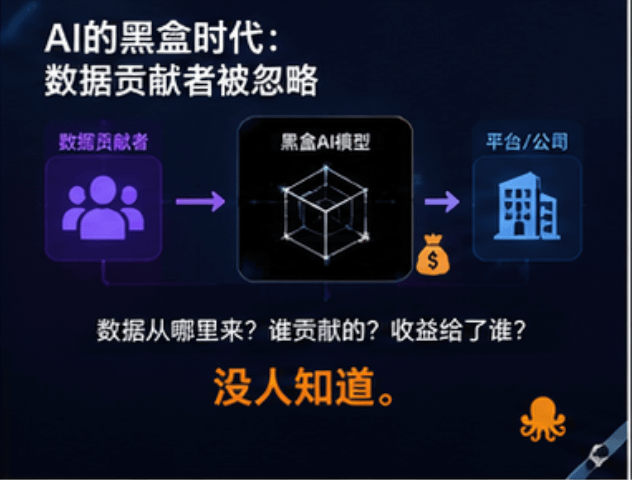
I grandi modelli di ora sono, in sostanza, come scatole nere.
Non hai idea di:
Da dove provengono i dati
Quali contenuti hanno partecipato all'addestramento
Chi ha contribuito valore
I profitti vanno a chi
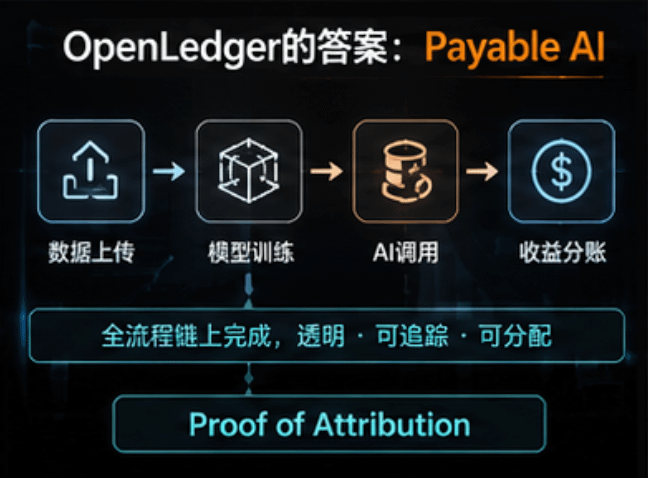
Ma OpenLedger ha proposto un concetto molto interessante:
Proof of Attribution.
Semplicemente,
Se l'AI ha usato i tuoi dati, il sistema può tracciarlo.
E poi la suddivisione automatica.
La prima volta che ho visto questo meccanismo, la prima parola che mi è venuta in mente è stata:
“Sistema di copyright AI”.
Nell'era di Internet passata, le piattaforme guadagnavano di più.
Poi, con l'era dei video brevi, i creatori di contenuti hanno iniziato a guadagnare.
E nell'era AI, ciò che avrà davvero valore potrebbe diventare:
Dati.
Perché l'AI non nasce dal nulla.
Ogni modello ha bisogno di enormi quantità di dati per essere nutrito.
L'AI medica ha bisogno di dati sui casi clinici.
AI finanziaria ha bisogno di dati di trading.
AI per giochi ha bisogno di dati sul comportamento dei giocatori.
AI legale ha bisogno di dati su casi giuridici.
La domanda è:
Questi dati, in passato, non hanno mai veramente appartenuto ai contributori di dati.
Quello che OpenLedger vuole fare è, in realtà, riportare questi “contributori invisibili” nel sistema di distribuzione del valore.
Questo punto lo considero particolarmente importante.
Perché ora molti progetti AI sono in competizione:
Agente
Meme
Capacità del modello
Prestazioni inferenziali
Ma pochi si preoccupano di risolvere:
“A chi appartengono i dati”
Questa questione.
E questo potrebbe proprio essere il più grande paradosso del futuro mondo AI.
Scoprirai che:
Più potente è l'AI, più costosi sono i dati.
Ma la realtà è che:
I dati delle persone comuni stanno diventando sempre più economici.
E molti non sanno nemmeno che stanno lavorando gratis per l'AI.
I contenuti che pubblichi, le tue abitudini di navigazione, i commenti che lasci, potrebbero già essere parte dell'addestramento dell'AI.
Ma i profitti non hanno nulla a che fare con te.
Ecco perché credo che la direzione di OpenLedger sia davvero intelligente.
Non ha continuato a competere con giganti come OpenAI su “grandi modelli”.
ma ha scelto un'altra strada:
SLM.
Vale a dire modelli specifici.

Ad esempio:
AI medica
AI legale
AI finanziaria
AI per giochi
Questi modelli verticali, in futuro, potrebbero essere più facilmente commercializzabili.
Perché risolvono problemi specifici del settore.
E ciò di cui queste industrie hanno più bisogno è:
Dati di alta qualità, tracciabili e con diritti di proprietà.
Quindi OpenLedger ha creato qualcosa chiamato Datanet.
Puoi interpretarlo come:
“Mercato dei dati AI”.
Dati di diversi settori formano diverse reti di dati.
I sviluppatori di modelli vengono qui per ottenere dati.
Applicazioni AI che chiamano modelli.
I profitti, attraverso la Proof of Attribution, tornano automaticamente ai contributori.
La cosa più interessante di questa logica è che:
È il primo tentativo di rendere il “lavoro dei dati” nel mondo AI quantificabile.
Le precedenti contribuzioni di dati erano invisibili.
I contributi di dati futuri potrebbero diventare un patrimonio.
Questo punto è davvero simile ai primi giorni di Internet.
All'inizio, tutti pensavano che i contenuti non avessero valore.
Poi ci siamo resi conto:
Il traffico è prezioso.
Poi abbiamo scoperto:
L'attenzione ha valore.
E ora, l'era AI potrebbe entrare in una nuova fase:
I dati hanno valore.
Anche credo che la più grande guerra AI del futuro non sarà necessariamente una guerra di modelli.
ma è:
Guerra sui diritti dei dati.
Chi possiede i dati, possiede il potere di parola nell'era AI.
Quello che OpenLedger sta facendo ora, in un certo senso, è tentare di stabilire:
L'“ordine economico dei dati” nel mondo AI.
Se alla fine questa cosa funzionerà, nessuno lo sa al momento.
Dopotutto, l'industria AI sta cambiando troppo velocemente.
Ma almeno mi ha fatto rendere conto per la prima volta:
Ciò che è veramente importante per l'AI potrebbe non essere il modello stesso.
Ma è:
quei contributori di dati che sono sempre stati trascurati.
Forse un giorno, le persone comuni non saranno più solo “carburante gratuito” nell'era AI.
Ma sono le persone che possono realmente partecipare alla distribuzione dei profitti dell'AI.
Se quel giorno dovesse davvero arrivare,
Quello che OpenLedger sta facendo ora potrebbe essere più importante di quanto molti pensino.

\u003cm-252/\u003e\u003cc-253/\u003e\u003ct-254/\u003e