

TL;DR: Pico Prism 2.0 dimostra i blocchi della mainnet di Ethereum a una media di 6,1 secondi con il limite attuale di gas di 60M della rete, con il 99,9% dei blocchi che si finalizzano entro il slot di 12 secondi. L'intera configurazione gira su 16 GPU RTX 5090 su due macchine per un costo hardware totale di circa $100K. Testato contro Pico Prism 1.0 sulla stessa base di gas di 60M, il nuovo sistema offre ~5,3 volte più efficienza nella prova per blocco.
A febbraio, abbiamo anticipato la transizione di Pico Prism a una configurazione dual-machine con 16 GPU, con i primi risultati sugli stessi blocchi benchmark da 45M di gas testati da Pico Prism 1.0.
Quella trasformazione è ora completa.
Pico Prism 2.0 è ufficialmente attivo, completamente ottimizzato e benchmarkato direttamente sui blocchi di produzione da 60M gas che Ethereum esegue oggi.
Il rilascio 2.0 è una ricostruzione completa dello stack attraverso l'ISA zkVM, l'architettura di prova distribuita, l'emulatore e il backend di prova GPU. Il risultato è un sistema che prova blocchi più grandi su un quarto dell'hardware utilizzato da Pico Prism 1.0, più veloce in media e si colloca esattamente sugli obiettivi di prova in tempo reale della Ethereum Foundation.
I risultati principali
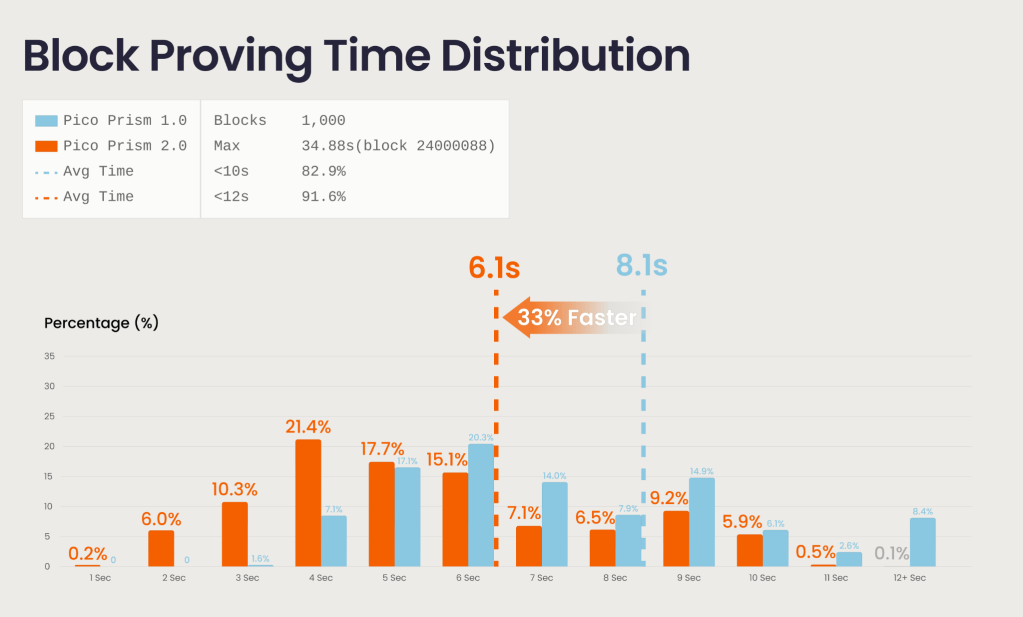
Pico Prism 2.0 è stato benchmarkato su 1000 blocchi consecutivi della mainnet Ethereum a partire dal blocco 24.000.000, sul limite attuale di gas di 60M della rete.
RisultatoMetricoTempo medio di prova6.1sBlocchi provati entro 12s 99.9%Hardware16 GPU RTX 5090 su 2 macchineCosto totale dell'hardware ~ $100KLimite di gas per blocco60M (Ethereum mainnet attuale)
Per un confronto equo, la configurazione a 64 GPU di Pico Prism 1.0 è stata testata nuovamente sugli stessi blocchi da 60M gas. Il sistema 1.0 ha una media di 8.1 secondi per prova. Pico Prism 2.0 raggiunge 6.1 secondi su un quarto dell'hardware, il che si traduce in un miglioramento di ~5.3x nel lavoro computazionale per blocco:
Pico Prism 1.0: 8.1s × 64 GPU ÷ 60M gas = 8.64 GPU-second per milione di gas
Pico Prism 2.0: 6.1s × 16 GPU ÷ 60M gas = 1.63 GPU-second per milione di gas
→ ~5.3× efficienza
Tra i principali obiettivi di prova in tempo reale della Ethereum Foundation ci sono una latenza media di prova inferiore a 10 secondi e un capex hardware on-prem sotto i $100K. Pico Prism 2.0 supera entrambi, funzionando su GPU consumer che qualsiasi team può acquistare al dettaglio.
I benchmark sono completamente riproducibili. I binari sono disponibili su https://github.com/brevis-network/pico-ethproofs.
Dentro Pico Prism 2.0
Quattro aggiornamenti arrivano insieme nel rilascio 2.0. Ognuno è significativo da solo e insieme producono un incremento di 5x.
1. Da RISC-V 32IM a RISC-V 64IM
L'ambiente di esecuzione zkVM di Pico è passato a RISC-V 64IM, sostituendo il precedente ISA a 32 bit. Il set di istruzioni a 64 bit corrisponde a come vengono scritti i programmi reali, dando a Pico un ambiente di esecuzione più ricco e tracce di esecuzione più brevi su maggior parte dei carichi di lavoro. Il sistema scambia un set di chip leggermente più elaborato per meno cicli per programma, e su blocchi reali, meno cicli è ciò che conta.
RISC-V 64IM è pienamente funzionale in Pico Prism 2.0. La verifica formale della nuova implementazione ISA è in corso.
2. Una nuova architettura a due macchine
Pico Prism 2.0 gira su due macchine, ognuna con 8 GPU RTX 5090, collegate tramite un interconnettore da 100 Gbps. Al centro c'è un pianificatore globale che opera come una bacheca di compiti condivisa per la pipeline di prova. Entrambe le macchine prelevano lavoro dinamicamente dal pianificatore piuttosto che ricevere assegnazioni staticamente partizionate.
L'architettura è costruita attorno a tre principi:
Pianificazione globale. I compiti non finiti vivono in un pool condiviso. Qualsiasi macchina può reclamarli man mano che si libera, mantenendo le GPU occupate invece di aspettare che il lavoro upstream si completi.
Località dei dati. Ogni macchina esegue indipendentemente la stessa emulazione e produce registrazioni locali coerenti. Il pianificatore ha solo bisogno di inviare indici di compiti piuttosto che pesanti artefatti intermedi. Dove i compiti locali sono disponibili, le macchine li preferiscono, mantenendo al minimo il traffico tra le macchine.
Massimo parallelismo. I compiti Combine e RISC-V chunk vengono prelevati dinamicamente dall'albero delle prove, con bilanciamento del carico autonomo su tutte le 16 GPU.
Il risultato è una pipeline di prova che si comporta come una coda di lavoro distribuita piuttosto che una sequenza fissa.
3. Emulazione Ahead-of-Time
L'emulatore di Pico Prism 1.0 interpretava i programmi in tempo reale, decodificando e inviando ogni istruzione al volo. L'emulatore 2.0 gira su Rust compilato nativamente generato direttamente da binari ELF, rimuovendo completamente l'overhead di decodifica e invio per istruzione.
L'efficienza del frontend conta più di quanto sembri, perché la prova in tempo reale è una pipeline bilanciata. Se l'emulazione non riesce a fornire lavoro alle GPU abbastanza velocemente, le GPU rimangono in attesa. La compilazione AOT rimuove una parte significativa di quel costo frontend e mantiene lo stack di prova continuamente alimentato.
4. Una riscrittura completa di CUDA
Il backend GPU di Pico è stato riscritto da zero, con ottimizzazioni profonde attraverso i componenti che si trovano sul percorso critico di ogni prova. L'impegno FRI ora utilizza LDE batch NTT adattivo, l'apertura FRI utilizza l'inversione batch di Montgomery, e il calcolo del quoziente passa attraverso un compilatore JIT con un IR di vincoli ottimizzato.
Lo stack riscritto fornisce guadagni di velocità immediati e offre una base più pulita e più estensibile per le future architetture GPU e i progressi del sistema di prova.
Guardando avanti
La corsa per la prova in tempo reale di Ethereum è stata la sfida definitoria dello spazio zkVM negli ultimi due anni. Nel dicembre 2025, la Ethereum Foundation ha dichiarato che la corsa delle prestazioni è praticamente vinta e ha spostato l'attenzione sulle fondamenta della solidità per l'integrazione L1 zkEVM attraverso il 2026.
Pico Prism 2.0 è il sistema di produzione per il lato delle prestazioni. Andando avanti, il lavoro continua sul lato della solidità. Brevis sta contribuendo attivamente insieme alla roadmap di sicurezza dell'EF per garantire che Pico Prism soddisfi l'obiettivo di sicurezza provabile a 128 bit fissato per l'integrazione L1 zkEVM, con la verifica formale del nuovo ISA RISC-V 64IM già in corso come parte di quel lavoro.
Nel marzo 2026, Brevis è stata selezionata come uno dei quattro team di prover nell'iniziativa On-Prem Proving della Ethereum Foundation attraverso Ethproofs. Il programma pilota finanziato il gruppo per provare 1 su 10 blocchi Ethereum L1 su hardware di proprietà sotto condizioni reali, testando se la prova ZK può scalare come infrastruttura decentralizzata piuttosto che dipendere da un pugno di fornitori di cloud. Il programma inizia a maggio 2026 ed è la cosa più vicina a una prova generale per l'integrazione live di L1 zkEVM.
Ogni passo su quel cammino avvicina Pico Prism a far diventare ZK parte dell'infrastruttura principale di Ethereum.
Circa Brevis
Brevis è una piattaforma di calcolo verificabile alimentata da prove a conoscenza zero, che funge da strato di calcolo infinito per Web3. Le applicazioni possono scaricare computazioni costose off-chain mentre provano ogni risultato on-chain. Lo stack di Brevis include Pico zkVM per calcoli di uso generale, il coprocessore di dati ZK per accesso senza fiducia ai dati storici della blockchain, Pico Prism per la prova dei blocchi Ethereum in tempo reale (99,8% di copertura su 16 GPU, raggiungendo l'obiettivo hardware di $100K della Ethereum Foundation), Vera per l'autenticità dei media provati da ZK e ProverNet, il marketplace decentralizzato per la generazione di prove ZK ora in esecuzione su mainnet. Fino ad oggi, Brevis ha generato oltre 340M di prove su più di 50 protocolli su oltre 8 blockchain.