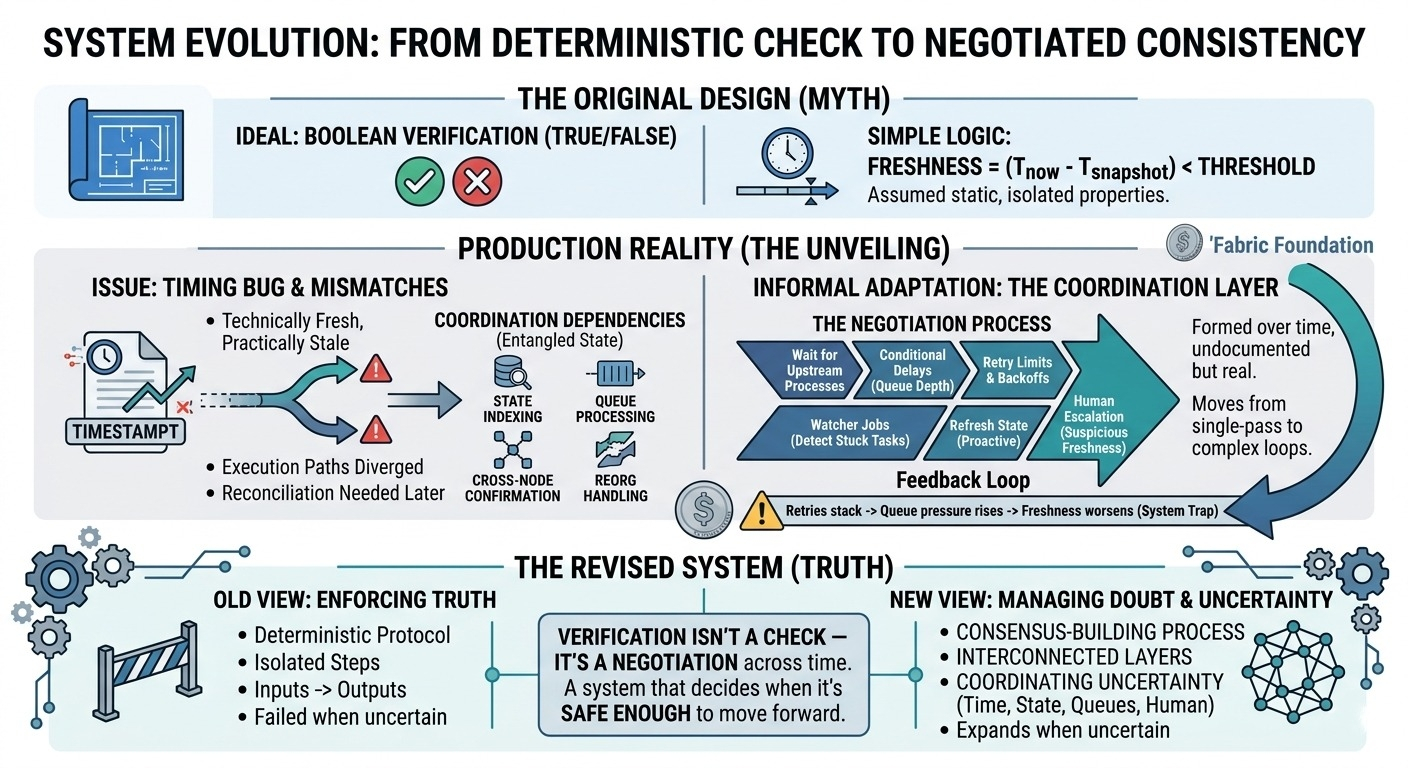
È iniziato come una piccola incoerenza in un passaggio di verifica.
Niente di critico. Solo un compito nel pipeline della Fabric Foundation che occasionalmente passava localmente ma falliva una volta che raggiungeva le code di produzione. Il compito era semplice: convalidare la freschezza dello stato prima di consentire un'esecuzione a valle legata alla $ROBO distribuzione della logica.
L'aspettativa era chiara.
Se lo snapshot dello stato è sufficientemente recente, procedere. In caso contrario, rifiutare e riprovare.
Ma la produzione non si è comportata in quel modo.
A volte lo snapshot era tecnicamente “fresco” per timestamp, eppure chiaramente obsoleto nell'effetto. Il sistema lo accettava, andava avanti, e solo più tardi vedevamo discrepanze—bilanci leggermente errati, percorsi di esecuzione che divergevano, lavori di riconciliazione che partivano ore dopo.
All'inizio, sembrava un bug di temporizzazione.
Abbiamo controllato la sincronizzazione dell'orologio tra i nodi. Nessun problema.
Abbiamo controllato i ritardi di propagazione. All'interno dei limiti accettabili.
Abbiamo persino inasprito la soglia di freschezza.
Non lo ha risolto.
Perché il problema non era solo il tempo.
Era coordinamento.
Il sistema presumeva che la freschezza potesse essere misurata come una proprietà statica. Un timestamp confrontato con "ora". Ma in realtà, la freschezza dipendeva da più processi asincroni: indicizzazione dello stato, elaborazione della coda, conferme tra nodi e gestione occasionale di riorganizzazioni.
Quindi "fresco" non era un punto nel tempo.
Era un obiettivo mobile plasmato dal carico del sistema e dal ritardo di coordinamento.
Non abbiamo ridisegnato il protocollo.
Abbiamo aggiunto i tentativi.
All'inizio, quelli semplici. Se la verifica falliva a monte, basta ripetere l'intero flusso dopo un ritardo. Questo ha ridotto gli errori visibili ma ha introdotto qualcos'altro: pressione sulla coda.
I tentativi hanno iniziato ad accumularsi. Le attività che avrebbero dovuto essere a passaggio singolo ora si ripetevano due, a volte tre volte. La lunghezza della coda è aumentata. La latenza è aumentata. E ironicamente, questo ha reso la freschezza peggiore.
Quindi abbiamo aggiunto delle protezioni.
Limiti di tentativo. Strategie di backoff. Ritardi condizionali basati sulla profondità della coda. Poi lavori di monitoraggio per rilevare attività bloccate. Poi aggiornamenti dei pipeline per aggiornare proattivamente lo stato prima che la verifica accadesse.
Ogni correzione era piccola. Locale. Ragionevole.
Ma nel tempo, hanno iniziato a formare uno strato.
Uno strato di coordinamento.
Non formalizzato. Non documentato come tale. Ma reale.
Ora, quando un'attività entra nel sistema, non si limita a "verificare ed eseguire".
Si muove attraverso una serie di accordi impliciti:
Aspetta abbastanza a lungo per i processi a monte.
Ripeti se a valle non è d'accordo.
Aggiorna lo stato se la fiducia diminuisce.
Esegui un'ispezione manuale se la deriva persiste.
Niente di tutto questo era nel design originale.
Eppure, questo è ciò che mantiene effettivamente stabile il sistema.
Lo chiamiamo ancora un passaggio di verifica.
Ma in realtà non sta verificando nulla in isolamento.
Sta negoziando coerenza attraverso il tempo.
Quella realizzazione ha richiesto del tempo.
Perché sulla carta, il protocollo sembra deterministico. Gli input entrano, gli output escono. La verifica applica la correttezza.
In produzione, però, il sistema sta coordinando l'incertezza.
Incertezza temporale.
Incertezza dello stato.
Incertezza della coda.
E sempre di più, attenzione umana.
Ora abbiamo dashboard che evidenziano "freschezza sospetta."
Gli operatori occasionalmente intervengono, non perché qualcosa sia rotto, ma perché il sistema non è abbastanza sicuro per procedere.
Quella parte è sottile.
Il protocollo non specificava l'intervento umano.
Ma il sistema è evoluto per dipendere da esso.
Non come un piano di emergenza. Come uno strato.
Quindi quando parliamo di Fabric Foundation e $ROBO garanzie di esecuzione, è allettante descrivere la logica, i contratti, le regole.
Ma questo non è il sistema completo.
Il sistema reale include tentativi che non erano destinati a essere permanenti.
Ritardi che codificano assunzioni sul coordinamento.
Osservatori che approssimano la fiducia.
E umani che colmano il divario quando l'automazione esita.
Alla fine, il passaggio di verifica non è fallito.
Si è espanso.
Silenziosamente.
E ora si tratta meno di controllare se qualcosa è corretto, e più di decidere quando è abbastanza sicuro andare avanti.
Questo è un tipo di sistema diverso.
Non uno che applica la verità.
Uno che gestisce il dubbio.
$ROBO @Fabric Foundation #ROBO