

La settimana scorsa stavo esaminando due rapporti di distribuzione ROBO da operatori che gestiscono flotte di ispezione.
La prima cosa che di solito controllo non è il tasso di completamento. È quanto rapidamente i sistemi migliorano tra le distribuzioni.
All'inizio, i numeri sembravano quasi identici. Il completamento dei compiti era costante. Il throughput della coda era stabile. Le ricevute di esecuzione registrate attraverso il livello di verifica di ROBO sembravano pulite.
Ma le curve di miglioramento non corrispondevano.
I robot di un operatore si stavano adattando molto più rapidamente a nuovi ambienti e condizioni di compito più complesse.
All'inizio presumevo che la spiegazione fosse hardware. Sensori migliori. Modelli di movimento migliori.
Per un momento sembrava plausibile.
Non era così.
La differenza apparve in dove andavano i dati delle attività dopo il completamento.
ROBO ha registrato la ricevuta di esecuzione. Ogni attività completata ha prodotto un record verificabile che la rete poteva osservare.
Ma il segnale comportamentale attorno a quel compito andò da un'altra parte.
Come si muoveva il robot. Dove esitava. Quali casi limite apparivano.
Quei dati tornarono direttamente nel sistema privato dell'operatore.
Il protocollo catturò il lavoro.
L'apprendimento è rimasto da un'altra parte.
Ho iniziato a monitorare un semplice proxy dopo: segnali comportamentali che sopravvivono all'esterno dell'operatore per 100 attività.
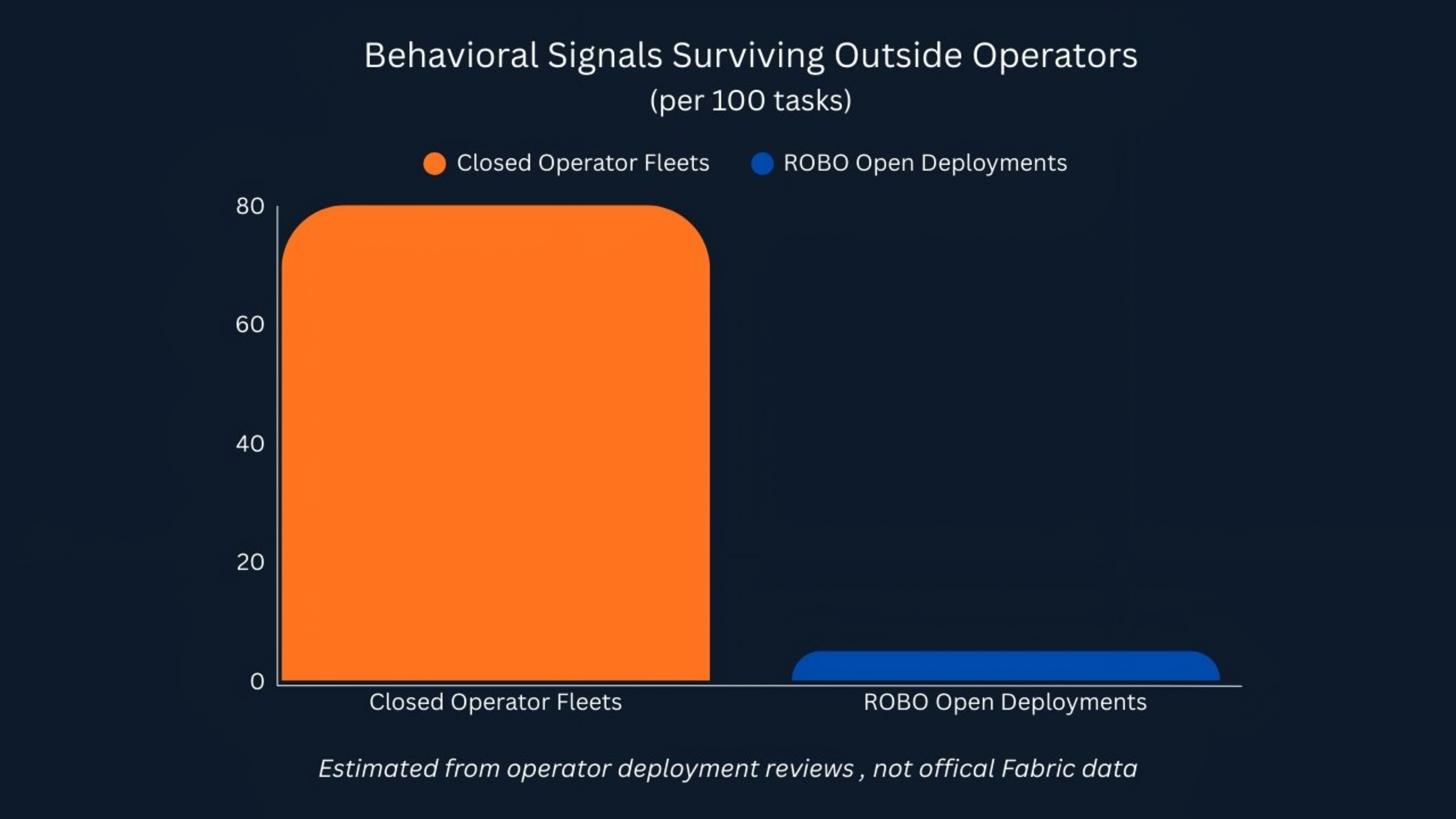
È allora che il modello è diventato ovvio.
In quasi tutte le distribuzioni aperte che ho esaminato, quel numero rimase vicino a zero.
Le ricevute erano pubbliche.
L'apprendimento non c'era.
Nella distribuzione dei robot, il ciclo di feedback diventa il fossato.
Gli operatori chiusi accumulano dati comportamentali ad ogni distribuzione. Questi dati migliorano la distribuzione successiva, che genera più segnali e affina nuovamente i modelli.
Pochi mesi dopo, i loro robot iniziano a prendere lavori che nessun altro toccherà.
ROBO coordina il lavoro tra i partecipanti. Ma se il segnale comportamentale generato da quel lavoro non lascia mai l'operatore che gestisce i robot, il ciclo di apprendimento rimane chiuso.
Il modello appare lentamente.
Gli operatori con dataset più ricchi iniziano a gestire compiti più complessi. I partecipanti alla rete aperta rimangono in ambienti più semplici. I nuovi arrivati partono dallo stesso punto di partenza ogni volta.
La rete rimane aperta.
Il ciclo di feedback non lo fa.
Il layer di mercato dei dati di Fabric mira a colmare esattamente quella lacuna. Se i dati comportamentali riguardanti le ricevute delle attività ROBO diventano parte di un dataset condiviso, l'apprendimento può iniziare a comporsi attraverso la rete invece di rimanere all'interno degli operatori individuali.
$ROBO è rilevante solo se la rete cattura effettivamente quell'apprendimento.
Se le ricevute delle attività rimangono pubbliche mentre i segnali comportamentali rimangono privati, la rete aperta coordina il lavoro mentre i sistemi chiusi continuano a diventare più intelligenti.
Quindi il vero test è semplice.
Man mano che le distribuzioni ROBO scalano, il segnale comportamentale attorno a quegli incarichi inizia ad accumularsi da qualche parte da cui la rete può apprendere?
O il ciclo di feedback rimane privato all'interno degli operatori che gestiscono i robot?