
Certo, i sistemi di intelligenza artificiale sono diventati straordinariamente capaci in un tempo sorprendentemente breve. Scrivono codice, compongono sinfonie, riassumono documenti legali e diagnosticano malattie a una velocità sovrumana. Sono disponibili in ogni momento, non si stancano mai e possono sintetizzare più informazioni in un secondo di quanto un esperto umano possa assorbire in una vita. La promessa che portano è enorme e comparabile, come afferma audacemente il whitepaper Mira, all'invenzione della stampa, della macchina a vapore, dell'elettricità e di Internet combinati.
Ma sotto questa superficie abbagliante si nasconde una crepa strutturale fondamentale: l'IA non può essere considerata costantemente corretta. Ogni grande modello linguistico è, nel suo nucleo, una macchina probabilistica. Non ragiona dai primi principi come gli esseri umani aspirano a fare. Prevede. Estrae. Approssima. E facendo così, fabbrica con sicurezza, fluentemente e senza rimorso un fenomeno che il mondo dell'IA chiama "allucinazione."
L'IA non sa cosa non sa. Riempe ogni lacuna con finzioni plausibili.
Penso che le conseguenze di questo difetto non siano astratte. Un'IA che allucina prescrivendo la dose sbagliata di farmaco può uccidere. Un'IA pregiudizievole che valuta le domande di prestito può radicare l'ineguaglianza sistemica per generazioni. Un'IA legale fiduciosa ma errata che redige un contratto può esporre un'azienda a responsabilità rovinose. Questi non sono futuri ipotetici. Questi sono gli interessi realistici di implementare l'IA di oggi in domini ad alta conseguenza.
La radice del problema è ciò che i ricercatori chiamano il dilemma dell'addestramento. Quando i costruttori di IA curano i dati di addestramento per eliminare le incoerenze migliorando la precisione e riducendo le allucinazioni, inavvertitamente incorporano i pregiudizi di chiunque abbia selezionato quei dati. Al contrario, addestrarsi su dati più ampi e diversificati riduce il pregiudizio ma crea un modello incline a produrre output contraddittori.
Modelli finemente sintonizzati offrono un certo sollievo. Un'IA medica addestrata esclusivamente su letteratura clinica sottoposta a revisione paritaria allucina meno riguardo alla medicina. Ma anche questi modelli ristretti crollano ai margini quando si presenta una situazione nuova al di fuori della loro distribuzione di addestramento, falliscono, spesso senza alcun segnale che stiano fallendo.
Controlla questo, ecco un diagramma a doppio asse che mostra la relazione inversa tra il tasso di allucinazione e il pregiudizio mentre l'ambito di addestramento del modello cambia il compromesso del dilemma di addestramento.
grafico semplice con due curve incrociate etichettate Rischio di Allucinazione e Rischio di Pregiudizio.
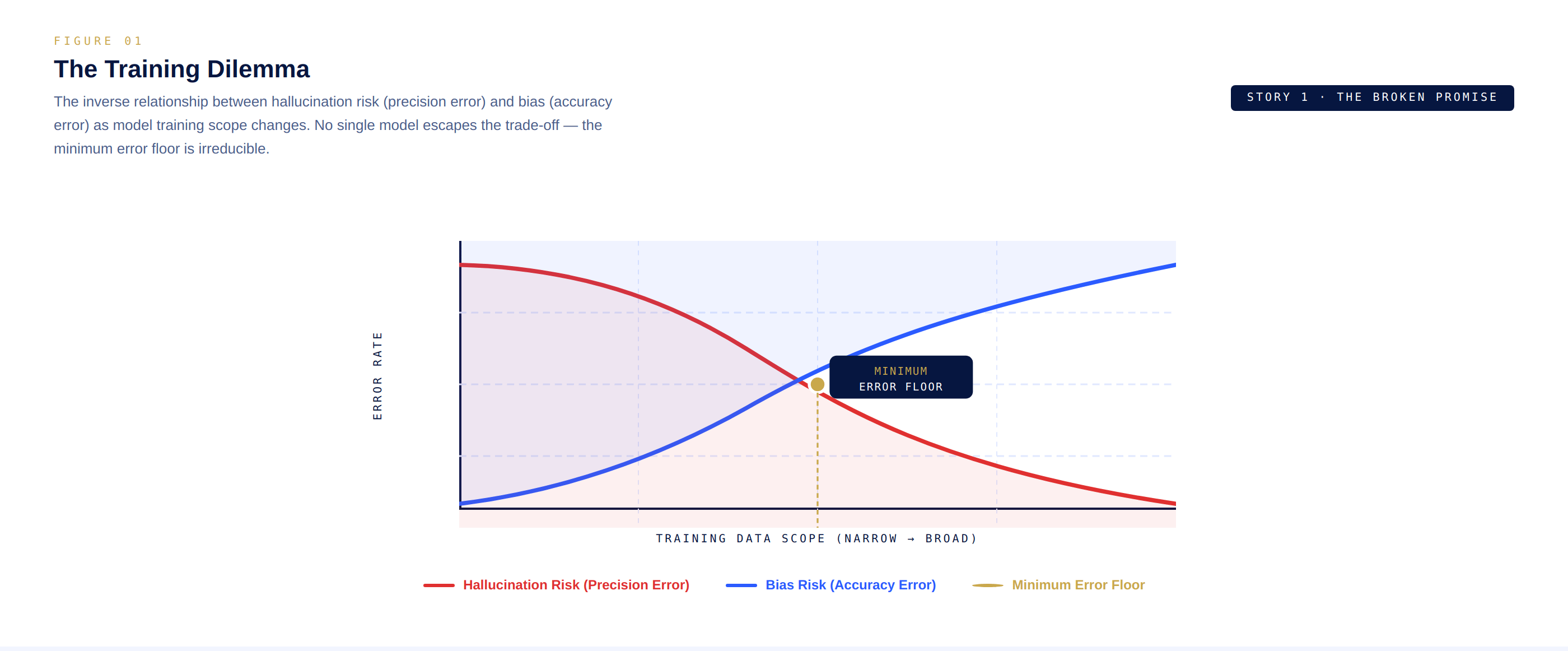
Questo crea ciò che gli architetti descrivono come un confine immutabile, un pavimento di errore minimo che nessun singolo modello, indipendentemente dalle dimensioni o dalla sofisticazione, può oltrepassare. Puoi investire maggiore potenza di calcolo. Puoi versare più dati. Puoi architettare reti più profonde. Ma il pavimento rimane. La natura probabilistica della tecnologia lo garantisce.
Questo non è un consiglio di disperazione. È un invito a pensare in modo diverso. La domanda non è "Come costruiamo un'IA perfetta?" La domanda è: "Come costruiamo un sistema che cattura gli errori dell'IA prima che causino danni?" Questa è la domanda a cui Mira è stata costruita per rispondere e la storia di come inizia qui.