Una rete di robot può elaborare compiti rapidamente e ancora fallire strategicamente se gli aggiornamenti delle politiche ritardano rispetto agli incidenti del mondo reale.
La maggior parte dei sistemi tratta la governance come documentazione statica mentre le operazioni cambiano ogni settimana. Quella lacuna crea un rischio silenzioso. Nuove modalità di fallimento appaiono, gli operatori improvvisano e le regole si allontanano dalla realtà fino a quando una disputa importante non costringe a un intervento d'emergenza. La velocità non è il collo di bottiglia in quel scenario. La reattività della governance è.
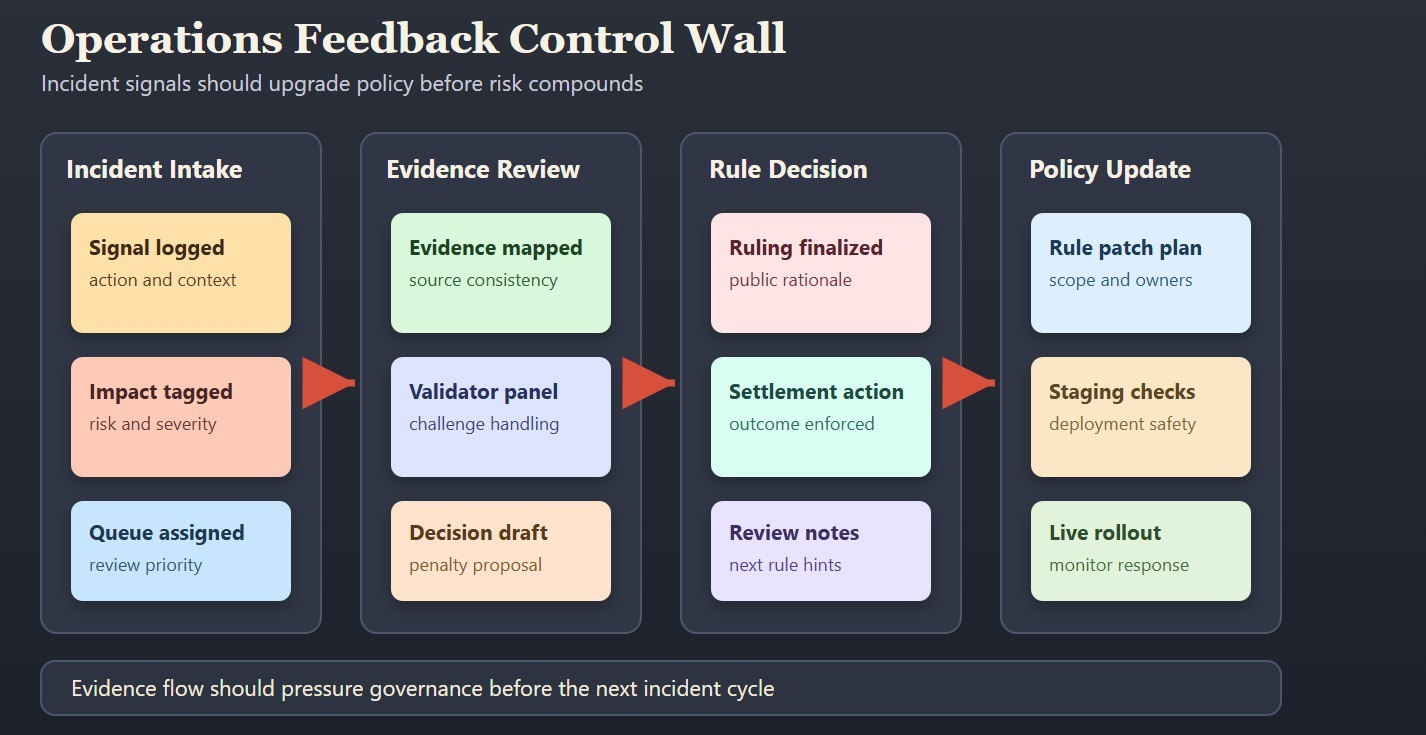
Il quadro di Fabric è utile perché lega il feedback di esecuzione a un modello di coordinamento pubblico invece di un ciclo di comitato chiuso. Le meccaniche delle sfide, l'economia dei validatori e i percorsi di regole visibili creano una struttura in cui le prove delle operazioni possono esercitare pressione sui cambiamenti politici prima che i danni si accumulino. Questa è una tesi di affidabilità più forte rispetto a "abbiamo buoni modelli e buone intenzioni."
Questo riformula anche il modo in cui leggo `$ROBO`. Il valore di utilità e governance dovrebbe derivare dall'uso reale della superficie di controllo: partecipazione al monitoraggio, allineamento degli incentivi e continuità dell'evoluzione delle regole sotto carico. Se quei meccanismi sono attivi, la rete può migliorare attraverso la pressione. Se sono inattivi, la governance diventa branding.
Per i team che implementano servizi di robotica a lungo termine, la domanda pratica non è se si verificano incidenti. Si verificheranno. La domanda chiave è se ogni incidente rende il sistema più governabile o più fragile.
Quando il prossimo risultato contestato del robot entrerà in produzione, il tuo strato di politica si adatterà attraverso prove pubbliche, o dipenderà da eccezioni private e dal ripristino della fiducia ritardato?
@Fabric Foundation $ROBO #ROBO