Un reclamo continua a ripetersi riguardo ai modelli di linguaggio di grandi dimensioni.
Sembrano autorevoli anche quando hanno torto.
Il pericolo non è solo l'allucinazione. È la fiducia stratificata sopra l'incertezza. Una risposta può essere strutturata, fluente e persuasiva pur contenendo ancora sottili errori fattuali o bias incorporato. Questo crea un rischio che la maggior parte degli utenti sottovaluta.

Alla base, i LLM operano su distribuzioni di probabilità. Predicono sequenze probabili, non verità verificate. La ricerca mostra che l'allucinazione non è un bug che scompare con la scala. È una limitazione intrinseca della generazione probabilistica. Tentativi di ridurre l'allucinazione attraverso una curatela dei dati più rigorosa spesso aumentano il bias. Espandere i dataset per ridurre il bias può aumentare l'incoerenza. C'è un trade-off strutturale da cui nessun singolo modello scappa completamente.
Questo diventa critico man mano che l'IA si sposta in domini di maggiore conseguenza. Sistemi di trading, strumenti di conformità, sommari medici, redazione legale, agenti autonomi. In questi ambiti, sembrare giusto non è sufficiente. Essere corretti è importante.
La questione più profonda è l'architettura. La maggior parte dei sistemi di IA si basa sulla validazione centralizzata o sulla supervisione umana. Questo non scala in un mondo in cui gli agenti IA operano continuamente e globalmente.
Questo è dove @Mira - Trust Layer of AI riformula il problema.
Invece di cercare di perfezionare un modello, MIira $MIRA introduce uno strato di verifica decentralizzato. Gli output dell'IA vengono scomposti in affermazioni granulari e indipendenti. Ogni affermazione è distribuita su più nodi verificatori. Questi nodi eseguono la propria inferenza e presentano giudizi che vengono aggregati in consenso.
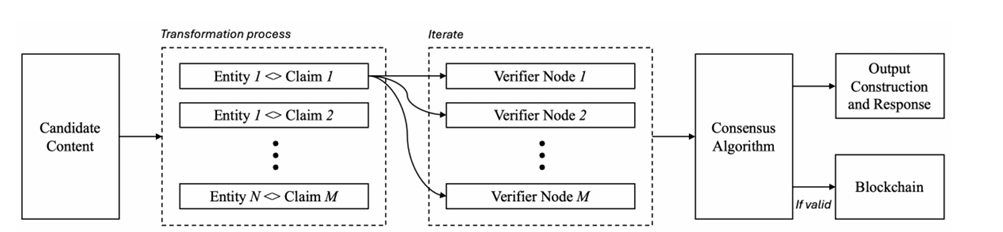
Ciò che rende questo diverso è lo strato economico. I validatori devono mettere in gioco valore. Se tentano di indovinare o si allontanano sistematicamente dal consenso, la loro partecipazione può essere ridotta. Il whitepaper quantifica persino come i ripetuti giri di verifica riducano drasticamente la probabilità di indovinare correttamente. Nel corso di più iterazioni, la manipolazione statistica diventa economicamente irrazionale.

C'è anche un beneficio strutturale nella decentralizzazione. Gli ensemble centralizzati riflettono ancora il bias di chiunque selezioni i modelli. Una rete senza permessi incoraggia la diversità negli approcci e nelle prospettive di formazione. Man mano che la partecipazione scala, il bias sistemico può essere diluito attraverso un consenso eterogeneo piuttosto che una curatela controllata.
La privacy è incorporata nel design. Gli output complessi vengono trasformati in affermazioni a livello di entità e frammentati casualmente, in modo che nessun singolo nodo ricostruisca l'intero contesto. La verifica avviene senza esporre documenti completi ai singoli operatori.
La visione più ampia va oltre il controllo della generazione post. L'obiettivo è integrare la verifica direttamente nella generazione stessa, fondendo inferenza e validazione in un processo unificato. Se raggiunto, questo sposterebbe l'IA da un output probabilistico verso un'affidabilità economicamente sicura.
Man mano che i sistemi di intelligenza artificiale iniziano a muovere capitale, automatizzare decisioni e plasmare il discorso pubblico, la domanda non è più quanto siano intelligenti.
La vera domanda è se i loro output possano essere fidati senza supervisione umana.
Questa è la lacuna strutturale $MIRA che si mira a colmare attraverso un'infrastruttura di verifica decentralizzata e allineata agli incentivi.