Le plus gros problème des bâtisseurs en IA aujourd'hui n'est pas l'accès aux modèles. C'est la confiance dans les données.
La plupart des bâtisseurs peuvent déjà accéder à des modèles puissants via des APIs. Le défi plus difficile commence lorsqu'ils ont besoin de données fiables pour améliorer ces modèles, affiner des cas d'utilisation spécifiques, ou construire des agents spécialisés. Les données proviennent de nombreuses sources, la qualité varie énormément, la propriété est souvent floue, et les contributeurs ont rarement une raison directe de continuer à fournir des informations utiles dans le temps.
Ça crée une situation étrange. Les bâtisseurs veulent une meilleure intelligence, mais le flux de travail utilisé pour produire cette intelligence est fragmenté. Les fournisseurs de données, les créateurs de modèles et les développeurs d'applications opèrent souvent dans des couches séparées avec des incitations différentes. Le résultat est des frictions, des cycles d'itération plus lents, et une incertitude quant à savoir si les données sous-jacentes restent utiles à mesure que les projets évoluent.
Ce que beaucoup de gens ne comprennent pas à propos d'OpenLedger, c'est qu'ils le voient principalement comme un autre projet d'IA en concurrence pour l'attention dans un marché déjà saturé.
L'angle le plus intéressant est qu'OpenLedger semble se concentrer sur la couche de coordination économique derrière le développement de l'IA. Le projet ne se contente pas de demander comment créer des modèles. Il s'interroge sur la manière dont les contributeurs, les ensembles de données, les modèles et les applications peuvent interagir de manière à ce que la création de valeur soit mesurable et que la participation reste durable.
Cette distinction est importante.
Le flux de travail traditionnel considère souvent les données comme une ressource à usage unique. Les données sont collectées, traitées et intégrées dans des modèles. Une fois cela fait, le lien entre le contributeur original et la génération de valeur future devient difficile à suivre. Les builders gagnent en intelligence, mais les structures d'attribution et d'incitation deviennent de plus en plus opaques.
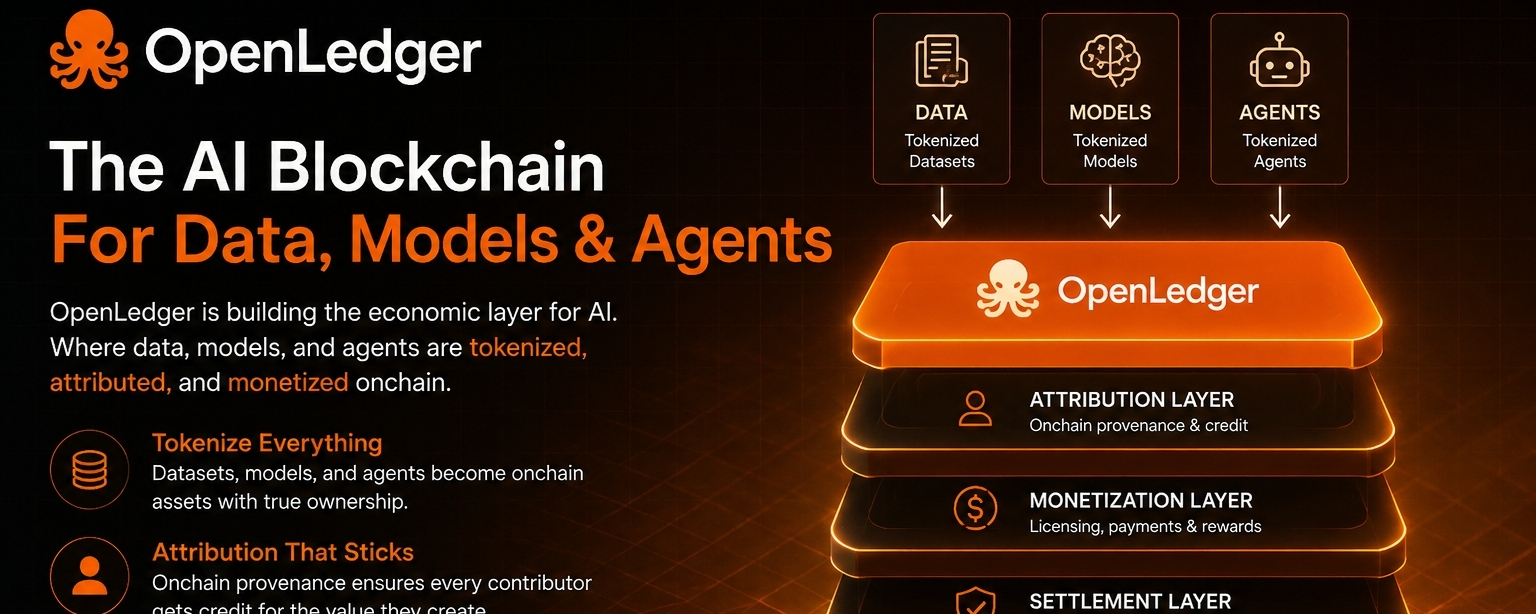
OpenLedger tente de réduire cette friction en introduisant une infrastructure où les données, les modèles et les agents d'IA peuvent exister au sein d'un cadre conçu pour l'attribution et la monétisation. Au lieu de considérer les données comme une entrée jetable, le système les traite comme un actif qui peut continuer à générer de la valeur tout au long du cycle de vie des applications d'IA.
La partie qui me frappe, c'est que cela déplace la conversation de la performance du modèle uniquement vers la responsabilité de la contribution.
Les builders parlent souvent de meilleurs modèles. Ils passent moins de temps à discuter de la manière dont la production de données durable se réalise réellement. Pourtant, de nombreux produits d'IA finissent par être contraints par la qualité des données plutôt que par la capacité brute du modèle. Si les contributeurs n'ont aucune raison de continuer à participer, la qualité des données se dégrade. Lorsque la qualité des données se dégrade, la performance des applications suit finalement.
C'est là que se situe le point de pression pour l'adoption.
Pour qu'OpenLedger ait de l'importance, les builders doivent décider que l'attribution et l'alignement des incitations sont suffisamment importants pour les intégrer dans leurs flux de travail. La technologie elle-même n'est qu'une partie de l'équation. Le défi plus large est comportemental. Les développeurs sont habitués aux pipelines existants, aux ensembles de données centralisés et aux outils d'IA établis. Toute nouvelle infrastructure doit réduire suffisamment la friction pour justifier un changement de ces habitudes.
Si ce changement se produit, les builders gagnent quelque chose de précieux : un chemin plus clair entre contribution et récompense. Les fournisseurs de données ont de meilleures raisons de participer. Les créateurs de modèles ont accès à des sources d'informations potentiellement plus riches. Les développeurs d'applications opèrent sur un système où les flux de valeur peuvent être suivis de manière plus transparente.
Considérez un scénario pratique.
Une équipe construisant un assistant de santé spécialisé a besoin de connaissances spécifiques au domaine que les modèles généralistes ne peuvent pas fournir de manière fiable. Ils nécessitent des contributions continues d'experts, de chercheurs et de sources de données de niche. Dans les structures traditionnelles, maintenir l'engagement des contributeurs devient difficile car la relation entre contribution et valeur future est faible.
Un cadre comme OpenLedger tente de créer une structure où les contributions restent visibles et économiquement connectées à l'intelligence produite. Au lieu de reconstruire constamment la participation à partir de zéro, les builders peuvent potentiellement opérer au sein d'un système conçu pour encourager la contribution à long terme.
Cela ne résout pas automatiquement le problème.
Un risque honnête demeure.
L'infrastructure peut créer des mécanismes d'attribution, mais elle ne peut pas forcer une participation significative. Si les contributeurs de haute qualité, les builders de modèles et les développeurs d'applications n'utilisent pas activement le réseau, le design économique devient moins pertinent. Les systèmes de coordination ne deviennent puissants que lorsque suffisamment de participants acceptent de coordonner à travers eux.
C'est pourquoi l'adoption du réseau est plus importante que l'architecture technique seule.
La thèse la plus forte autour d'OpenLedger n'est pas qu'il aide à créer de l'IA. De nombreux projets poursuivent déjà cet objectif. La thèse plus forte est qu'il tente de réduire l'une des inefficacités structurelles les plus persistantes de l'IA : la déconnexion entre ceux qui contribuent à l'intelligence et ceux qui en capturent la valeur. Si les builders considèrent de plus en plus l'attribution des données et l'alignement des incitations comme une infrastructure nécessaire plutôt que comme des fonctionnalités optionnelles, l'approche d'OpenLedger devient beaucoup plus facile à comprendre.
