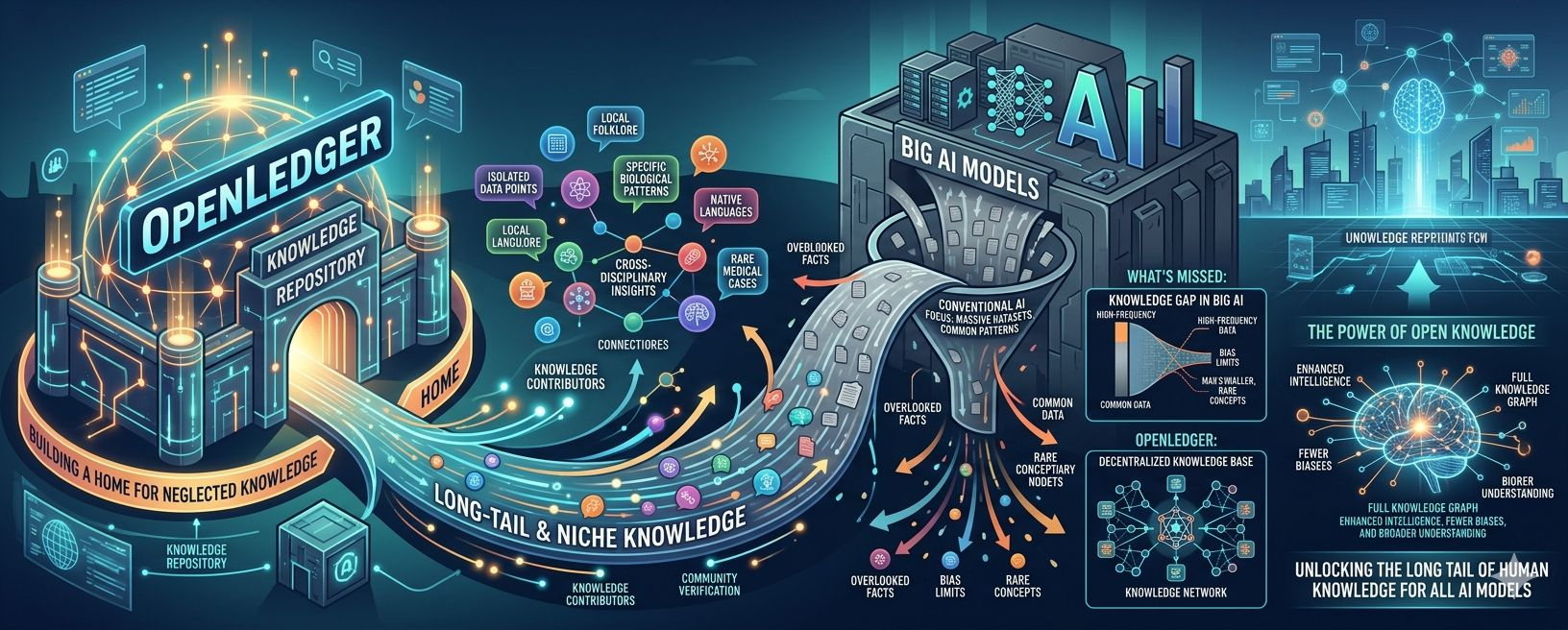
Most people do not notice the limits of general AI until they ask it something that actually matters.Not a casual question. Not a broad explanation. Not “write me a caption” or summarize this topic.” I mean the kind of question where the answer has to understand a specific world. A world with its own rules, shortcuts, mistakes, language, history, and quiet details that outsiders never see.
That is where big general models often begin to wobble.
They can sound smooth. They can sound certain. They can explain almost anything at the surface level. But once the subject becomes narrow enough, once the question belongs to a real industry or a real community, the weakness becomes obvious. The model knows the shape of the answer, but not always the weight of it.
OpenLedger is interesting because it is trying to work in that gap.Not the glamorous gap. Not the one that makes easy headlines. The harder one: the gap between general intelligence and useful intelligence.
OpenLedger is building infrastructure for AI that is connected to specific data, specific contributors, specific models, and specific use cases. Its focus is not simply to create another chatbot or another AI tool with a cleaner interface. The project is trying to create a network where knowledge can be contributed, traced, used to train specialized models, and rewarded when that knowledge creates value.
That sounds technical, but the idea behind it is very human.
People know things. Communities know things. Developers, researchers, analysts, traders, auditors, doctors, lawyers, engineers, teachers, gamers, builders, and niche online groups all hold knowledge that general AI does not fully capture. Some of that knowledge is too specific. Some of it changes too quickly. Some of it lives in scattered documents, private experience, technical discussions, or community memory.
OpenLedger is trying to give that knowledge a place to become useful.The project is built around a simple frustrationThe AI world has a data problem, but not in the way people usually describe it.
There is plenty of data. Too much, actually. The internet is full of text, images, code, comments, papers, posts, documents, and conversations. The problem is not only quantity. The problem is ownership, quality, relevance, and trust.
Most large AI models are trained on massive pools of information. That gives them range, but it also creates distance. The people who created the original value often disappear. The source of an answer becomes unclear. The expert behind the knowledge receives nothing. The user gets an output, but cannot always tell what shaped it.
OpenLedger is approaching this from another direction.Instead of treating data as something that gets swallowed into a black box, the project wants to make data visible as an asset. It wants contributors to be connected to the value their data creates. It wants models to have clearer relationships with the datasets that trained them. It wants AI builders to use specialized knowledge without pretending that all knowledge is equal.
That is the project’s real center.OpenLedger is not only saying, “AI needs more data.”It is saying, “AI needs better data, and the people who provide it should not be invisible.”
Why narrow knowledge matters
The phrase “narrow knowledge” can sound small, almost unimportant. But in reality, narrow knowledge is often the most valuable kind.
A general model may explain decentralized finance, but a protocol auditor knows the exploit pattern that appears only under certain conditions. A general model may explain tax rules, but a local accountant knows where people actually make mistakes. A general model may describe a medical process, but a specialist knows which small detail changes the decision. A general model may summarize a software framework, but a maintainer knows why something breaks in production.
This is the kind of knowledge OpenLedger is trying to unlock.
The project is built for a future where AI is not one giant model trying to answer everything. Instead, it imagines many specialized models, each trained on sharper, cleaner, more relevant datasets. These models do not need to know the whole internet. They need to know one domain well.
That matters because the next stage of AI will not be judged by how impressive it sounds. It will be judged by whether it works inside real workflows.
A business does not need a model that can talk about every industry. It needs one that understands its own industry. A developer does not need a generic coding assistant that gives half-right suggestions. They need one that understands the stack, the risks, the documentation, and the common failure points. A crypto user does not need an AI agent that speaks confidently about wallets. They need one that understands routes, fees, contracts, permissions, and risk.
OpenLedger’s project is aimed at that more practical future.What OpenLedger is actually trying to build
At its core, OpenLedger is building an AI-focused blockchain network where data, models, and AI agents can be connected through attribution and incentives.
The project uses the idea of community-owned datasets. These datasets can support specialized AI models. Contributors provide knowledge or data. Builders use that data to train or improve models. When those models are used, the system is designed to recognize the contribution behind them.
This is where OpenLedger’s idea of attribution becomes important.
Attribution means the system should be able to identify which data contributed value. In ordinary AI systems, this is usually hidden. You ask a question, you get an answer, and the source of the intelligence is often unclear. OpenLedger wants to make that relationship more transparent.
That does not only matter for fairness. It matters for trust.
Whan an AI system gives an answer in a serious domain, people want to know why they should believe it. They want to know what kind of knowledge sits underneath the output. They want to know whether the model was trained on generic internet content or actual domain-specific material.
OpenLedger is trying to build infrastructure where that background is not completely buried.
The project’s bigger vision is a marketplace of intelligence. Not just raw data. Not just models. Not just AI agents. A full network where all of these pieces can interact, and where the value created by AI can flow back to the people who helped create it.
The project is not only about AI. It is about ownershipThis is where OpenLedger separates itself from many AI projects.
A lot of AI platforms are built around access. They give users access to a tool, an API, or a model. OpenLedger is thinking more about ownership and contribution. Who owns the data? Who benefits from it? Who gets rewarded when a model becomes useful? Who can prove that their knowledge mattered?
These are not small questions.
For years, the internet has trained people to give away knowledge casually. People write tutorials, answer forum questions, publish research notes, share code, create guides, explain problems, review products, and document mistakes. That information becomes useful to everyone. But when AI systems learn from it, the original contributor usually gets no direct benefit.
OpenLedger is trying to challenge that pattern.
It is saying that data should be treated as something with economic value. It is saying that specialized knowledge should not disappear into a model without trace. It is saying that contributors should have a role in the AI economy beyond being silent suppliers.
That idea is powerful because it speaks to a growing discomfort around AI. People are beginning to ask whether AI is being built on top of human effort without returning enough value to the people who made that effort useful.
OpenLedger’s answer is to create a system where contribution can be recorded, attributed, and rewarded.Why blockchain fits into the projec
The word “blockchain” can make people impatient. In some projects, it feels forced. A normal app gets a token, a vague decentralization story, and a pitch deck full of big claims.But in OpenLedger’s case, the blockchain layer has a clearer purpose.
If the project wants to track data contribution, model usage, attribution, and rewards, it needs a shared record. It needs a way for different participants to interact without relying entirely on one central company to decide who gets credit. Blockchain gives the project a way to make parts of that system transparent, verifiable, and programmable.
That does not mean blockchain magically solves everything. It does not. Bad data can still exist. Incentives can still be abused. Attribution can still be technically difficult. But the blockchain layer makes sense for the kind of economy OpenLedger wants to build.
The project is not using blockchain only as a payment rail. It is using it as the coordination layer for AI contribution.That is an important distinction.
OpenLedger wants data contributors, model builders, app developers, and users to operate inside one connected system. The blockchain helps organize value across that system. It creates a structure where data is not just uploaded and forgotten, but linked to downstream usage.
In simple terms, OpenLedger is trying to make AI contribution trackable.The role of specialized models
OpenLedger’s focus on specialized models is one of the most important parts of the project.
The AI market is slowly moving from fascination with giant models to demand for useful models. Large general models will remain important, but they are not always the best fit for every task. In many cases, a smaller model trained on the right data can be more practical than a larger model trained on everything.
Specialized models can be cheaper to run. They can be easier to improve. They can be more accurate inside a specific domain. They can be built around clear datasets instead of broad internet knowledge. They can also be more understandable to the communities that use them.
OpenLedger is building for that shift.
The project imagines a world where different communities create different knowledge networks. A finance-focused dataset can support a finance model. A blockchain security dataset can support a security model. A healthcare workflow dataset can support a medical operations model. A legal dataset can support a legal assistant. A gaming community can train models around its own economy, strategies, and culture.
This is not about replacing general AI completely.It is about giving serious use cases better tools.
A general model is useful when the question is broad. A specialized model is useful when the question is deep.
OpenLedger’s project becomes more important when AI agents enter the pictureAI is moving beyond answers. It is moving toward action.
That changes everything.
When AI only writes text, mistakes are easier to catch. When AI starts acting on behalf of users, mistakes become more expensive. An AI agent might move funds, interact with smart contracts, search markets, route transactions, manage workflows, or make decisions based on live data.
In that world, vague intelligence is not enough.
An agent needs domain knowledge. It needs reliable context. It needs access to trusted datasets. It needs to understand the environment where it is acting. It also needs accountability.
OpenLedger’s infrastructure is relevant here because agents will need specialized intelligence. A crypto wallet agent, for example, should not rely only on generic language ability. It should understand wallets, chains, fees, permissions, risks, bridges, swaps, liquidity, contract behavior, and user intent. That kind of intelligence depends on focused data.
OpenLedger’s project is positioned around this future: AI agents powered by specialized models, trained on attributed datasets, operating inside a network where contributors can share in the value.
That is more concrete than simply saying “AI and crypto will merge.”
OpenLedger is trying to build one of the layers where that merge could actually happen.
The project’s strongest idea is fairness, but its hardest challenge is quality
The strongest emotional idea behind OpenLedger is fairness.
People who provide useful knowledge should be rewarded. Communities that create valuable datasets should not be treated as disposable. AI should not be built only by extracting from everyone and paying only the platform owner.
That idea is easy to support.
The harder part is quality.
A reward system attracts contributors, but it can also attract noise. If people are paid to provide data, some will provide bad data. Some will duplicate existing material. Some will try to manipulate the system. Some will produce volume without value.
For OpenLedger to succeed, it needs more than incentives. It needs strong filtering, reputation, validation, and performance measurement. It needs to know which datasets are actually useful. It needs to protect specialized models from becoming polluted by weak or misleading inputs.
This is especially important because the project is dealing with knowledge that may be used in serious contexts.
If an AI model is trained for entertainment, low-quality data is annoying. If it is trained for finance, law, medicine, security, or business operations, low-quality data can be dangerous.
So OpenLedger’s real challenge is not only to collect data. It is to build trust around data.
That will decide whether the project becomes meaningful infrastructure or just another marketplace with a nice idea.
What makes OpenLedger different from ordinary AI platforms
The difference is not that OpenLedger uses AI. Everyone uses AI now.
The difference is that OpenLedger is trying to build an economy around the ingredients of AI.
Most AI platforms focus on the final product. The user sees a chatbot, assistant, dashboard, or app. The work behind it is hidden. The data is hidden. The contributors are hidden. The model history is hidden.
OpenLedger is more interested in the hidden layer.
It wants to expose and organize the relationship between data, models, agents, and users. It wants to create a network where intelligence is not only consumed but also contributed to and monetized.
That gives the project a different personality.
It is not just selling intelligence. It is trying to structure how intelligence is made.
That is a much harder project, but also a more meaningful one.
The human side of the project
The most interesting thing about OpenLedger is not the technology by itself. It is the kind of person the project could empower.
There are people sitting on valuable knowledge who do not have the resources to build an AI company. They may have data, experience, documents, workflows, or domain understanding. But turning that into a model, distributing it, and earning from it is not easy.
OpenLedger is trying to lower that barrier.
A ontributor should be able to bring useful data into the network. A builder should be able to use thhat data to improve a model. A user should be able to benefit from a sharper AI system. And the value should not flow in only one direction.
That is the human promise of the project.
It gives smaller experts and niche communities a possible role in the AI economy.
Not everyone needs to build a giant model. Not everyone needs to compete with the biggest labs. Some people know one area extremely well. In the future OpenLedger imagines, that may be enough.
Why the project feels relevant now
OpenLedger feels timely because AI is entering a more serious phase.
The early excitement was about what AI could say. The next stage is about what AI can reliably do. That shift creates demand for better data, clearer attribution, specialized models, and systems that users can trust.
General AI will continue to be useful, but it will not answer every professional need. The world is too detailed for that. Every serious field has its own hidden map. OpenLedger is trying to build a way for those maps to become part of AI without losing their owners along the way.
That is why the project matters.
It is not trying to make knowledge broader. It is trying to make narrow knowledge more powerful.
A grounded view of OpenLedger’s future
OpenLedger has a strong concept, but the project still has to prove itself through execution.
The idea is promising: bring specialized data on-chain, connect it to AI models, track attribution, reward contributors, and support AI agents and applications. But the practical work will be difficult. The project will need real datasets, real builders, real demand, and real proof that its attribution system works at scale.
It will also need to avoid the trap that catches many crypto-AI projects: speaking in huge visions while users wait for useful products.
The market does not need another project that says AI will change everything. It needs tools that make AI more trustworthy, more specialized, and more economically fair. OpenLedger’s success will depend on whether it can deliver that in a way people actually use.
Still, the direction is important.
The future of AI should not belong only to the largest companies with the largest models. It should also include the smaller communities with the sharpest knowledge. It should include people who understand one field deeply. It should include contributors whose work has been useful for years but rarely rewarded directly.
OpenLedger is trying to open that door.
And if it works, the result will not just be better AI. It will be a different relationship between knowledge and value.
The internet has always been full of people who know things that matter. Some of that knowledge is broad and public. Some of it is buried in small groups, technical corners, local industries, and lived experience. General models can miss it because they are built to see everything at once.
OpenLedger is making the opposite bet.
It is betting that the future will belong not only to the biggest intelligence, but to the most relevant intelligence. Not only to models that can talk about anything, but to models grounded in knowledge that came from somewhere, belongs to someone, and can be traced back to the people who made it useful.
