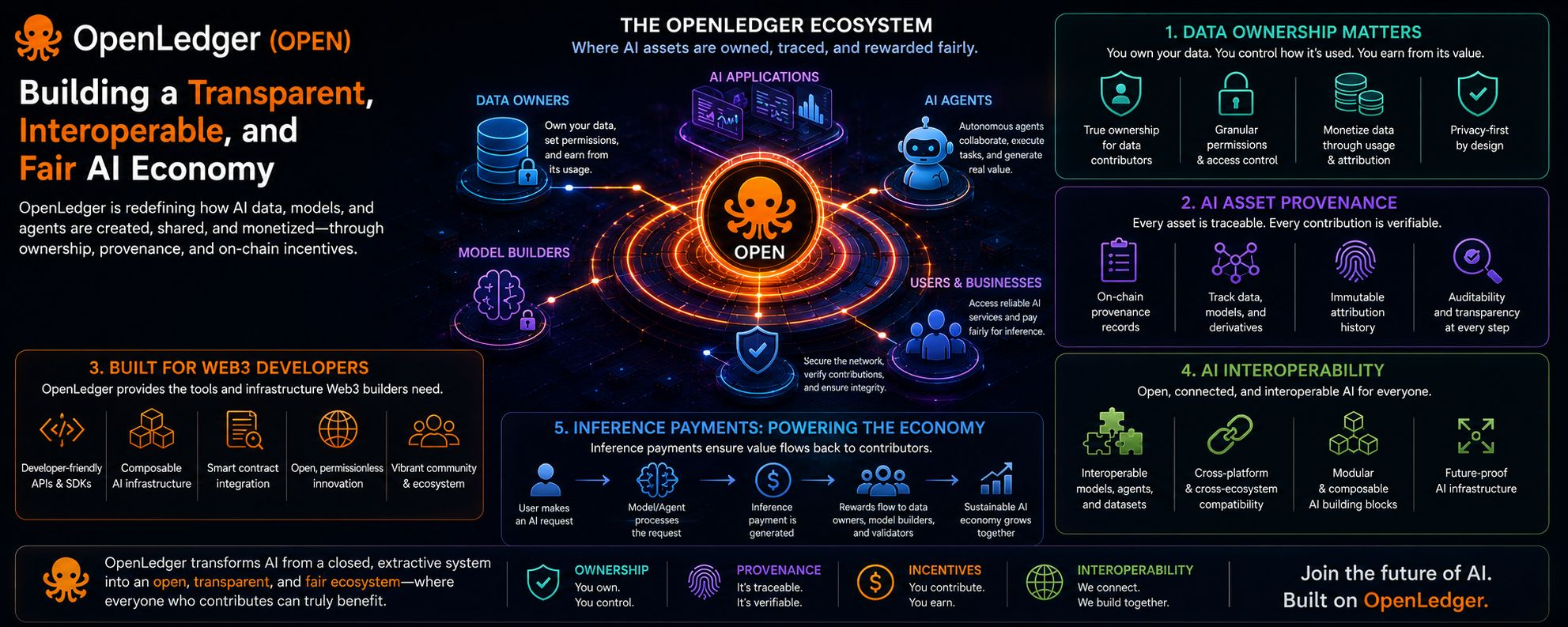

He estado revisando OpenLedger de nuevo, y creo que el proyecto está atacando sigilosamente uno de los problemas más pasados por alto en la IA: la propiedad. Todos hablan sobre modelos y poder de cómputo, pero casi nadie menciona quién realmente posee la inteligencia cruda que alimenta estos sistemas 😂 En este momento, los datos se están rastrillando, reutilizando, ajustando y monetizando a gran escala, mientras que los contribuyentes generalmente pierden visibilidad y control por completo.
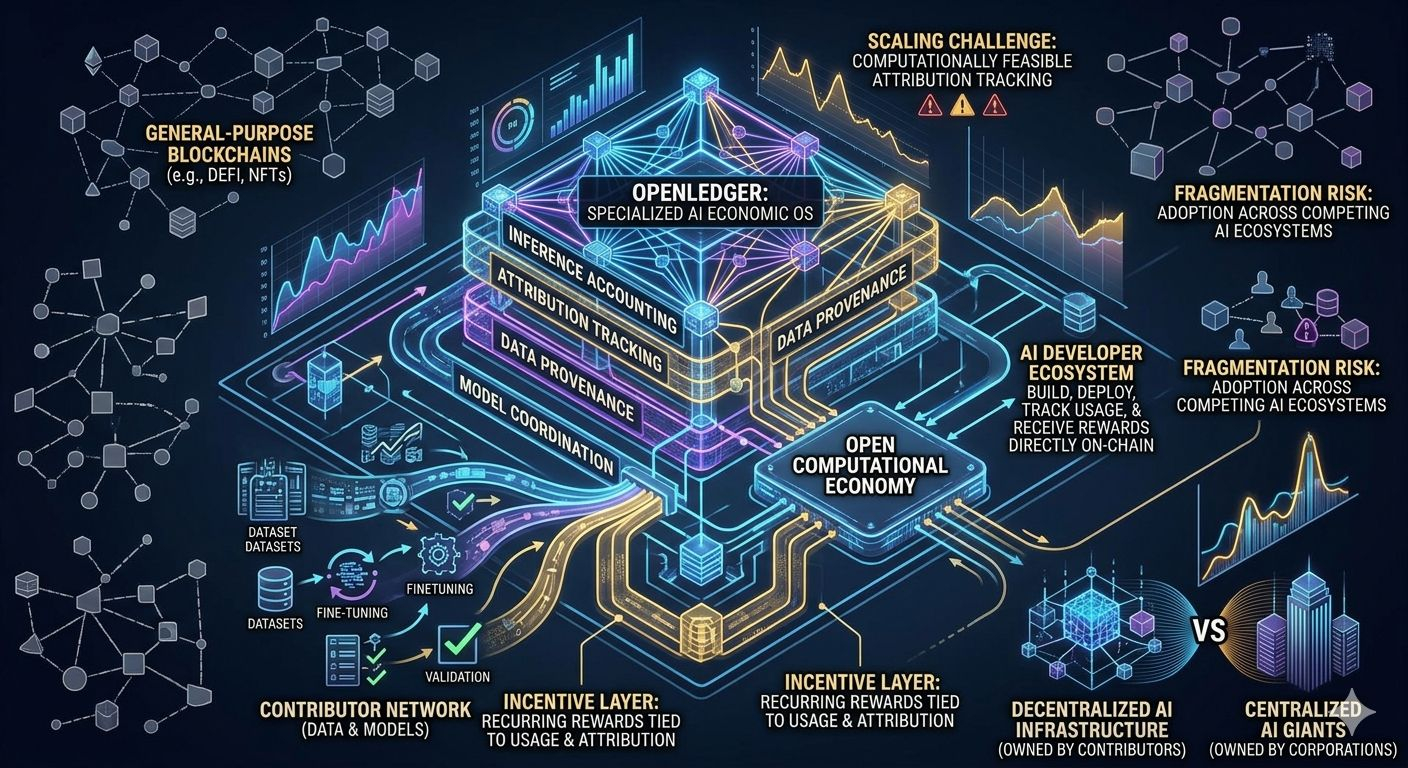
Ahí es donde toda la arquitectura de OpenLedger empieza a volverse interesante.
Lo que seguía volviendo a pensar es cuán seriamente la red trata la propiedad de los datos y la procedencia. En lugar de que las bases de datos se conviertan en recursos invisibles en el backend, OpenLedger intenta convertirlas en activos económicos trazables. Cada contribución puede teóricamente llevar metadatos de atribución a lo largo del ciclo de vida del entrenamiento de modelos, implementación y generación de inferencias. Esa capa de procedencia importa más de lo que la gente se da cuenta porque los sistemas de IA están volviéndose cada vez más composables. Los modelos se construyen sobre bases de datos, los agentes interactúan con otros agentes, y las salidas evolucionan a través de múltiples capas de infraestructura de inteligencia.
Sin un seguimiento de la procedencia, nadie realmente sabe de dónde proviene el valor ya.
Y honestamente, esa es también la razón por la cual los desarrolladores de Web3 parecen naturalmente atraídos hacia este ecosistema. OpenLedger no solo añade blockchain a las narrativas de IA para marketing. La cadena en sí está estructurada alrededor de la atribución transparente, la coordinación descentralizada y los incentivos económicos programables. Los desarrolladores pueden desplegar aplicaciones de IA, integrar bases de datos, coordinar agentes y recibir recompensas basadas en inferencias directamente en la cadena sin depender completamente de proveedores de IA centralizados.
El ángulo de interoperabilidad también está subestimado. La mayoría de los sistemas de IA hoy en día operan como reinos aislados con comunicación limitada entre modelos, bases de datos e infraestructuras. OpenLedger empuja hacia una interoperabilidad económica compartida donde los agentes de IA, aplicaciones y modelos pueden interactuar a través de capas de atribución y pago estandarizadas. Eso crea una economía de IA más modular en lugar de ecosistemas fragmentados bloqueados detrás de APIs corporativas.
Y el mecanismo de pago por inferencia podría ser en realidad el motor central detrás de todo. Siempre que las salidas de IA generen valor, los pagos pueden fluir teóricamente de vuelta a través de la red hacia los contribuyentes cuyas bases de datos, modelos o agentes habilitaron esa inferencia. Eso transforma la economía de la IA de extracción en participación. En lugar de que una sola empresa capture todos los ingresos posteriores, el sistema intenta distribuir las recompensas proporcionalmente entre los contribuyentes.
Pero la tensión aquí es obvia también.
Los sistemas con alta atribución se vuelven increíblemente difíciles de mantener a medida que las interacciones de IA se vuelven más autónomas y en capas. Cuanto más interoperable se vuelve el ecosistema, más difícil es calcular los límites de propiedad justa con precisión. También existe el riesgo de que los sistemas de contribución tokenizados incentiven la cantidad sobre la calidad.
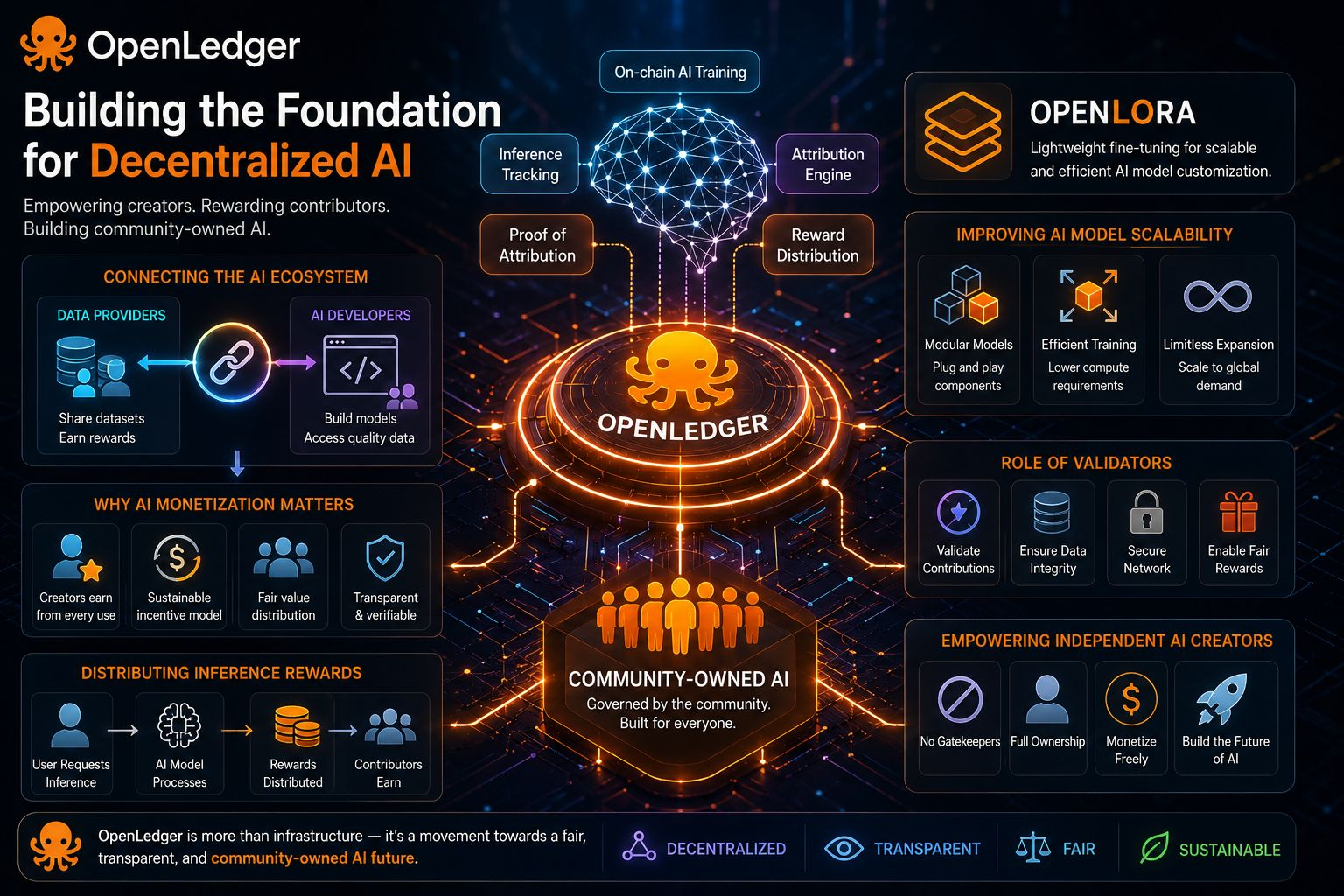
Aún así, OpenLedger se siente direccionalmente importante porque recontextualiza los datos de IA como infraestructura propia en lugar de combustible público gratuito. La verdadera pregunta es si los sistemas de procedencia descentralizados pueden mantenerse escalables una vez que las economías de IA se vuelvan demasiado complejas para que los humanos las auditen completamente.
