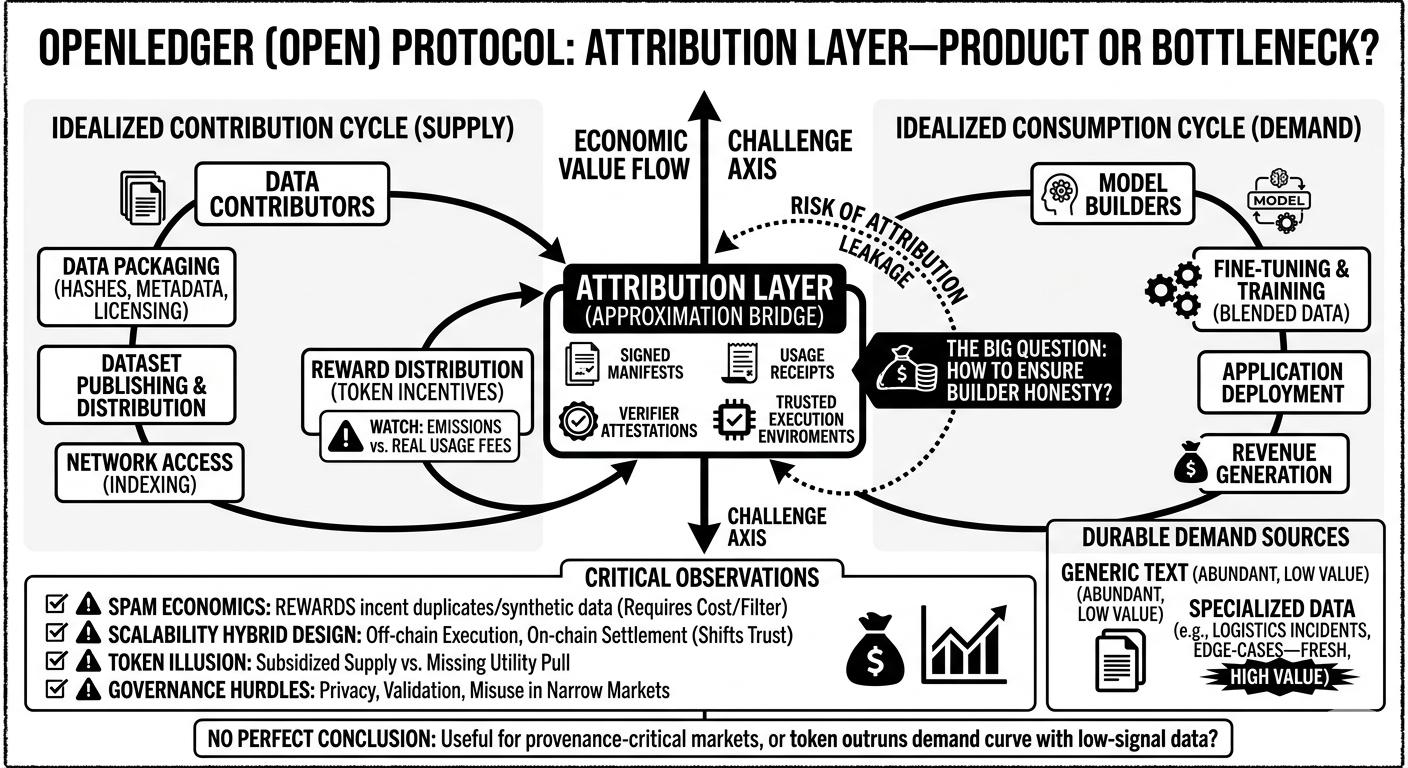
he estado revisando la documentación de arquitectura de openledger y algunos desgloses técnicos, centrándome principalmente en cómo conectan los flujos de datos de IA con la coordinación en la cadena. lo que me llamó la atención es que no solo están construyendo una capa de conjunto de datos descentralizada, sino que están tratando de construir una trazabilidad económica alrededor de los propios datos. es decir: si un modelo utiliza algún conjunto de datos, el protocolo debería teóricamente saber lo suficiente para enrutar recompensas de vuelta a los contribuyentes con el tiempo.
eso suena limpio conceptualmente. en la práctica, sinceramente, se siente como si todo el sistema dependiera de si la atribución puede sobrevivir al contacto con flujos de trabajo de IA en el mundo real.
la mayoría de la gente piensa que openledger es solo otro token de IA + cripto donde los contribuyentes suben datos y ganan recompensas. pero la arquitectura en realidad hace una suposición más grande: que el desarrollo futuro de la IA dependerá de mercados de datos abiertos y componibles en lugar de tuberías mayormente privadas. no estoy completamente convencido de que esa suposición sea incorrecta, pero es bastante importante.
el sistema de contribución de datos descentralizado es probablemente la parte más fácil de entender. los contribuyentes empaquetan conjuntos de datos con hashes, metadatos, información de licencia, tal vez un historial de versiones. el protocolo indexa y distribuye estos datos a través de la red. bastante claro. la parte difícil es el control de calidad. si las recompensas están ligadas a las subidas, el spam se vuelve económicamente racional casi de inmediato. conjuntos de datos sintéticos, corpora duplicados, versiones ligeramente modificadas de muestras existentes: todo eso aparecerá rápido a menos que la publicación tenga algún costo o mecanismo de filtrado.
y esta es la parte en la que sigo pensando... atribución. openledger parece posicionar la atribución como el puente entre la IA y la economía cripto. pero la atribución de entrenamiento es desordenada por defecto. una vez que un modelo entrena en conjuntos de datos mezclados, la influencia de las contribuciones individuales se vuelve difícil de aislar. así que el protocolo probablemente se basa en aproximaciones: manifiestos de entrenamiento firmados, recibos de uso, atestaciones de verificación, tal vez entornos de ejecución confiables eventualmente. pero ninguno de esos resuelve completamente el problema de '¿cómo sabemos que el creador está diciendo la verdad?'
también hay una capa de mercado que se sitúa sobre esto. el flujo ideal es obvio: los contribuyentes proporcionan datos → los creadores de modelos los consumen → las aplicaciones generan ingresos → las recompensas fluyen hacia atrás a través del gráfico de atribución.
pero sigo preguntándome dónde comienza la demanda duradera. los conjuntos de datos de texto genéricos ya son abundantes. el mercado más creíble es el de datos especializados que cambian con frecuencia o requieren experiencia en el dominio. imagina una empresa de logística afinando un modelo de enrutamiento utilizando informes de incidentes reales de almacenes y registros de entregas en casos límite. esos datos tienen un valor operativo real porque son frescos y difíciles de conseguir públicamente. openledger podría coordinar esas contribuciones mejor que una plataforma cerrada en teoría, especialmente si los contribuyentes quieren una compensación transparente. pero entonces heredas todos los problemas de gobernanza difíciles en torno a la privacidad, la validación y el uso indebido.
la capa de incentivos del token es donde las cosas se vuelven más turbias para mí. se supone que open debe coordinar la participación entre contribuyentes, validadores/verificadores, tal vez también operadores de modelos. pero las emisiones de tokens pueden crear una extraña ilusión de demanda. puedes tener mucha 'actividad' en la red sin una verdadera atracción del lado de los compradores. esto sucede en muchos proyectos de infraestructura cripto: la oferta se subsidia mucho antes de que exista utilidad.
la pregunta sobre la escalabilidad también importa. los flujos de trabajo de IA generan enormes cantidades de computación fuera de la cadena. openledger no puede verificar realísticamente cada paso de entrenamiento o llamada de inferencia directamente en la cadena. así que el diseño de la red termina siendo híbrido casi por necesidad: ejecución fuera de la cadena, compromisos en la cadena y liquidación. eso probablemente sea aceptable, pero significa que la confianza se desplaza hacia quien controle la capa de verificación.
¿quién realmente crea valor aquí? los contribuyentes crean opcionalidad, no valor garantizado. los constructores crean productos e ingresos, pero también son el lugar más fácil para que ocurra la fuga de atribución. así que el protocolo asume implícitamente que el informe honesto se vuelve económicamente preferible al engaño. tal vez a través de staking, auditorías, reputación o expectativas de los compradores sobre la procedencia. sigue sintiéndose sin resolver.
observando:
porcentaje de recompensas financiadas por tarifas de uso reales vs emisiones de tokens
compradores de conjuntos de datos repetidos en lugar de experimentos impulsados por incentivos únicos
tasas de spam/disputa en conjuntos de datos contribuidos
si la verificación de atribución se mantiene ligera o se vuelve operacionalmente costosa
aún no hay una conclusión perfecta. puedo ver a openledger volviéndose útil para mercados de coordinación de datos estrechos y de alto valor donde la procedencia realmente importa. pero también puedo imaginar un futuro donde los incentivos del token superen la curva de demanda real y la red se llene de contribuciones de bajo valor.
la pregunta abierta para mí sigue siendo bastante simple: una vez que los incentivos se normalicen, ¿qué realmente obliga a los creadores de modelos a seguir participando honestamente en el sistema de atribución en lugar de evadirlo por completo?