
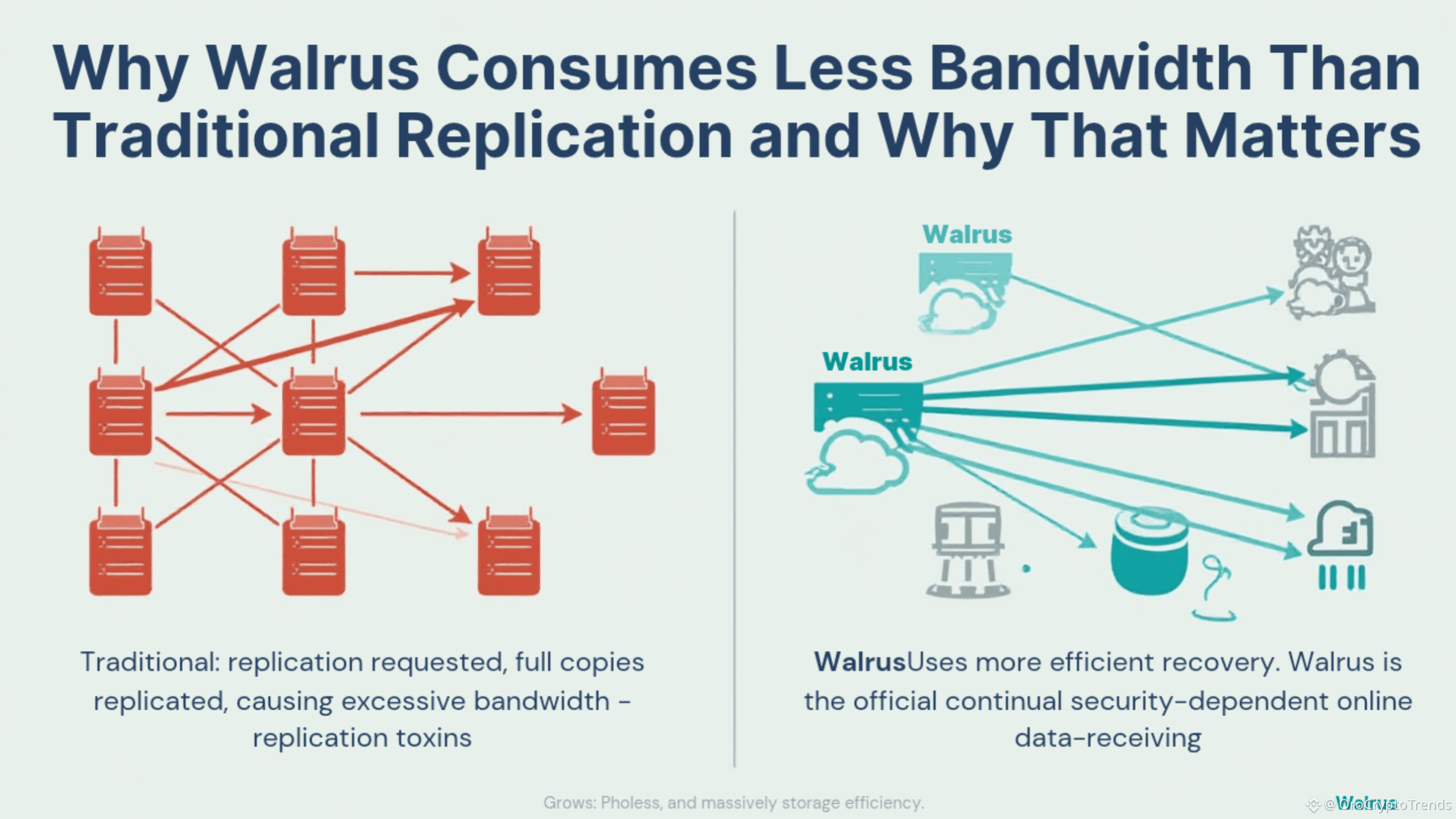
Anyone who’s worked with distributed storage or blockchain systems knows that moving data around isn’t just a technical detail—it’s often the hardest, most resource-intensive part of the whole operation. Classical systems have long relied on replication: the age-old strategy of protecting your data by making complete, redundant copies across different machines. If you want to survive multiple failures, you simply make more copies. It’s easy to grasp, easy to implement, and for a long time, it was the go-to solution.
But there’s a catch: replication is incredibly bandwidth-hungry. Each new replica is a full copy, and every time a machine fails, the process of rebuilding isn’t subtle—it means shoving the entire dataset across the network again. Multiply that by thousands or millions of users, and you’re suddenly looking at huge network costs, congestion, and painfully slow recovery times. When your infrastructure scales up or stretches across continents, this model quickly becomes unsustainable.
Enter protocols like Walrus (and its peers, such as RedStuff), which turn the traditional approach on its head by leveraging erasure coding. This isn’t just a minor tweak; it’s a fundamental change in how data durability and availability are achieved.
Understanding Replication’s Bandwidth Baggage
Let’s dig deeper into why replication is so bandwidth-intensive. Imagine you have a dataset you want to protect against hardware failures. To survive two simultaneous node crashes, you’d make three full copies and distribute them across three machines. Sounds solid, but the bandwidth costs add up fast. Every gigabyte of data you store is actually tripled in transit—once for each replica. And it doesn’t stop there.
If a node fails, the system needs to rebuild the lost replica. But instead of just transferring the missing chunks, the naive replication model typically means sending the entire dataset over the network, even if only a tiny portion was actually lost. This process repeats every time a node goes down, needs maintenance, or is replaced. When your system is global, with sites in different regions or countries, the resulting network traffic can overwhelm your links and balloon your operational expenses.
And as datasets grow—not just in size, but in the number of copies needed for higher reliability—the replication approach starts to show its age. Add more nodes, more redundancy, and the bandwidth costs don’t just grow linearly—they can explode, especially during recovery scenarios.
How Walrus Uses Erasure Coding to Slash Bandwidth Usage
Walrus brings a smarter solution to the table through erasure coding, a mathematical technique that breaks up data into smaller pieces (shards) and then generates coded fragments from those pieces. Instead of storing three complete replicas, Walrus might break your data into 10 parts and create 6 additional coded fragments, resulting in 16 fragments in total. The key is that you only need any 10 out of those 16 fragments to reconstruct your original data.
This approach offers several massive advantages:
1. Bandwidth-Efficient Storage: When you first upload data, each node only receives a single fragment, not the whole dataset. This means the total amount of data sent across the network is much closer to the size of your original data plus a bit of coding overhead—not a multiple of it, as with replication. The process is more distributed, so no single network link becomes a bottleneck.
2. Lightweight Recovery: Here’s where erasure coding truly shines. If a node fails, the system doesn’t need to copy the whole dataset to a new node. Instead, it requests just enough fragments from the surviving nodes to reconstitute what was lost. Often, this is only a fraction of the total data, drastically reducing the amount of recovery traffic. Not only does this speed up recovery times and minimize downtime, but it also keeps your network far less congested, even as your system scales.
3. Flexible and Scalable Protection: With erasure coding, you can tailor the number of fragments and the level of redundancy to fit your exact requirements for durability and availability. Need to survive more failures? Add more fragments. Want to optimize for bandwidth? Tweak the ratio. This flexibility is simply unattainable with rigid replication.
Why This Is a Game-Changer for Decentralized Systems
Think of it like rebuilding a lost library. Replication is like making complete photocopies of every book and handing them out to different librarians. Every time you lose a librarian, you have to copy every single book all over again, regardless of how many books went missing. It’s simple, but incredibly wasteful.
With Walrus and erasure coding, it’s as if each librarian holds a unique set of summaries and indexes. If you lose one, you don’t need to re-copy the entire library—you just gather a few summaries from the remaining librarians and reconstruct the lost knowledge. It’s faster, requires less effort, and doesn’t flood your hallways with paper.
This efficiency isn’t just a technical curiosity—it’s a critical advantage for modern, global, decentralized storage networks. In many cases, bandwidth is the most limited and expensive resource, especially when nodes are spread across different cloud providers, countries, or even continents. Walrus’s approach means:
- Lower ongoing costs, because you’re not constantly duplicating data over expensive links.
- Faster recovery, minimizing downtime and improving reliability.
- Less network congestion, so your system remains responsive even during failure scenarios.
- Better scalability, since adding more data or more nodes doesn’t come with a bandwidth explosion.
In a world where data is growing faster than ever and systems are expected to be both resilient and efficient, the old ways just can’t keep up. Replication is easy to grasp, but it’s a blunt tool for today’s challenges. Protocols like Walrus, with their erasure-coded designs, demonstrate what’s possible when we rethink the fundamentals. You get stronger protection, smarter recovery, and a fraction of the bandwidth consumption.
For architects and engineers building the next generation of decentralized, high-performance systems, these bandwidth savings aren’t just nice to have—they’re essential. As data continues to flow across the globe, the move from brute-force replication to intelligent erasure coding is rapidly becoming the new standard for anyone who cares about efficiency, scalability, and resilience.
Not financial advice.

