I still remember a moment when I was trying to execute a simple DeFi vault interaction late at night. Everything looked fine on the interface, but after signing the transaction, it just sat there pending, unchanging, no clear signal of what was happening underneath. I found myself switching between wallet, explorer, and dashboard more than I should have, not because I expected a failure, but because the system gave me very little structure to understand its current state. That small moment of uncertainty made me rethink what “reliable execution” actually means in DeFi.
Over time, I’ve noticed this is not an isolated experience. It repeats in different forms across many protocols. When networks get busy or when multiple actions compete for execution space, the user experience stops being about completion and becomes about interpretation. You are no longer just waiting for confirmation you are trying to infer system behavior from partial signals. And in my experience watching 0n chain systems evolve, that interpretability gap islS often more painful than the delay itself.
What I find important here is that the issue is not just congestion in the usual sense. It feels more like a coordination problem between intent, execution, and verification layers. Every transaction enters the system as if it exists in a clean pipeline, but under real load, that pipeline becomes contested. Ordering changes, verification queues grow, and execution paths start interacting in ways the user never directly sees.
I often compare this to a city traffic system during rush hour where there are no adaptive signals or structured priorities. Cars don’t just move slowly they start to behave unpredictably. Some lanes clear up randomly, others stall without explanation, and the flow becomes harder to reason about. The core problem isn’t just volume; it is the absence of a system level policy that governs how movement should adapt under stress.
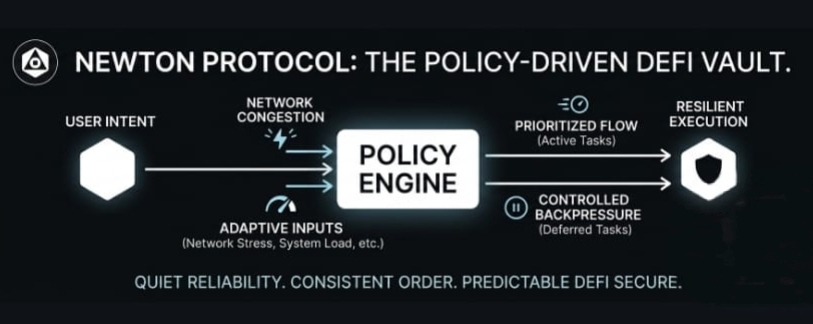
When I look at how @NewtonProtocol approaches this, what caught my attention is the emphasis on a policy engine that sits above execution for vault operations. Instead of treating each transaction as an isolated event that simply enters a queue, the system introduces a structured layer that defines how actions should be handled depending on conditions like system load, verification state, or risk context.
What I noticed is that this shifts the design away from purely reactive execution. From a system perspective, that is a meaningful change. Execution is no longer only determined by external competition in the mempool or by block ordering. It is also shaped by internal policy rules that influence whether an action should proceed immediately, be delayed, or be processed differently under congestion.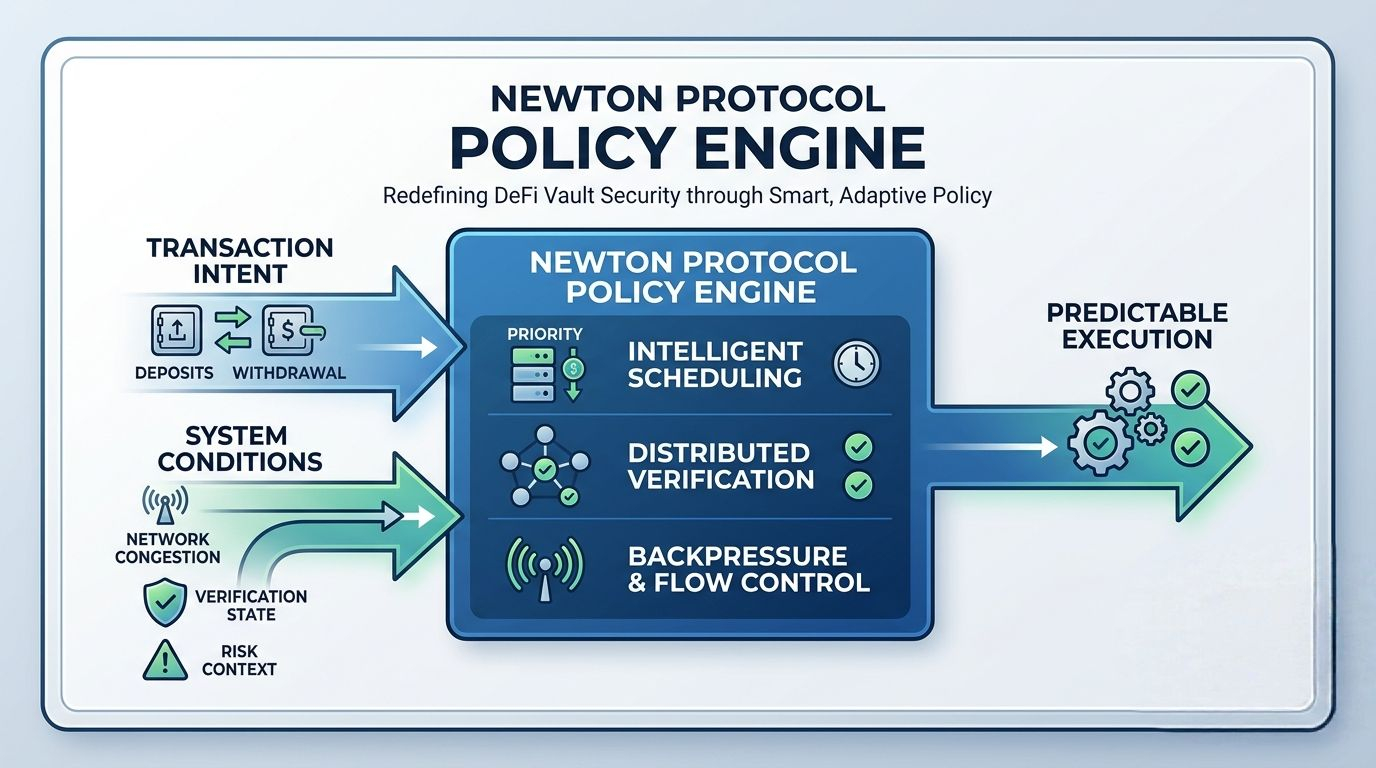
Scheduling becomes more intentional in this model. Instead of a simple first come first served structure, tasks can be interpreted through policy conditions before they are even executed. That means the system can prioritize certain vault actions when conditions are stable, or apply controlled delays when the network is under pressure. what matters in practice is not just speed, but whether behavior remains predictable when demand fluctuates.
Verification flow also becomes more distributed in this kind of architecture. Rather than forcing every operation through a single linear path, verification can be split across multiple workers or nodes. This improves scalability, but more importantly, it reduces the risk of bottlenecks forming in one part of the system. The challenge, of course, is maintaining consistency across parallel execution paths, ensuring that even if tasks are processed differently, the final outcome remains aligned with policy rules.
Another aspect I keep coming back to is congestion handling. In most systems, congestion is treated as something to absorb until limits are reached. But with a policy driven structure, congestion can be managed more deliberately through backpressure. Instead of letting overload cascade through the system, the flow can be slowed, reshaped, or temporarily paused to protect downstream execution layers. That shift from passive stress absorption to active flow control feels important in how resilience is defined.
Workload distribution ties all of this together. A resilient system is not one where every node behaves identically under load, but one where tasks are dynamically assigned based on current conditions and system policies. That flexibility is what allows execution environments to remain stable even when demand is uneven or unpredictable.
Stepping back, what stays with me is a simple observation. In DeFi infrastructure, performance is often discussed in terms of throughput or latency. But in real usage, what actually matters is consistency under stress the ability of a system to behave in a predictable way even when everything around it becomes noisy.
Good infrastructure does not need to constantly prove itself. It simply keeps order when conditions become unstable, and that quiet reliability is often what defines its real strength...