

Die Zukunft von KI-Apps und Agenten auf OpenLedger
Thema
Openledger
Tags
OpenLedger
Übersicht über den Beitrag
Von spezialisierten Modellen zu Agenten, die sehen, logisch denken und handeln können — dieser Blog erklärt, wie OpenLedger die Zukunft von KI-Agenten und -Anwendungen definiert, mit Kontext, Tools, Gedächtnis und Logik, die in die Chain integriert sind.
In den frühen Phasen des maschinellen Lernens wurden die meisten Systeme als monolithische Modelle entwickelt, die einmal trainiert und dann eingefroren wurden. Im Laufe der Zeit hat sich die Branche in Richtung Feinabstimmung und aufgabenspezifische Varianten entwickelt. Diese Modelle bildeten die Grundlage für die Anpassung an verschiedene Bereiche, aber nützliche KI-Anwendungen heute zu erstellen, bedeutet, das Modell zu stärken, damit es mehr leisten kann.
Ein leistungsstarkes Modell ist nur ein Teil der Gleichung. Damit KI-Systeme sinnvoll in der realen Welt agieren können, müssen sie ihren Problembereich verstehen, mit Live-Daten interagieren, historischen Kontext abrufen und deterministische Logik ausführen. So wie GPUs das Skalieren für das Training ermöglichten, besteht der nächste Sprung darin, Interaktion, Attribution und wirtschaftliche Ausrichtung auf der Anwendungsebene freizuschalten.
Dies ist die Infrastruktur, die OpenLedger bereitstellt.
OpenLedger ist die KI-Blockchain. Sie wurde nicht als allgemeine Kette entworfen, sondern als Ausführungs- und Attributionsschicht für intelligente Systeme. Sie bietet das Substrat, in dem Modelle, Daten, Gedächtnis und Agenten interoperable Komponenten werden. Dieser Blog beschreibt die Werkzeuge, die Modelle erweitern werden, um eine Vielzahl von Agenten und Anwendungen zu ermöglichen, indem sie den Kontext, das Verhalten und das Gedächtnis hinzufügen, die sie benötigen.
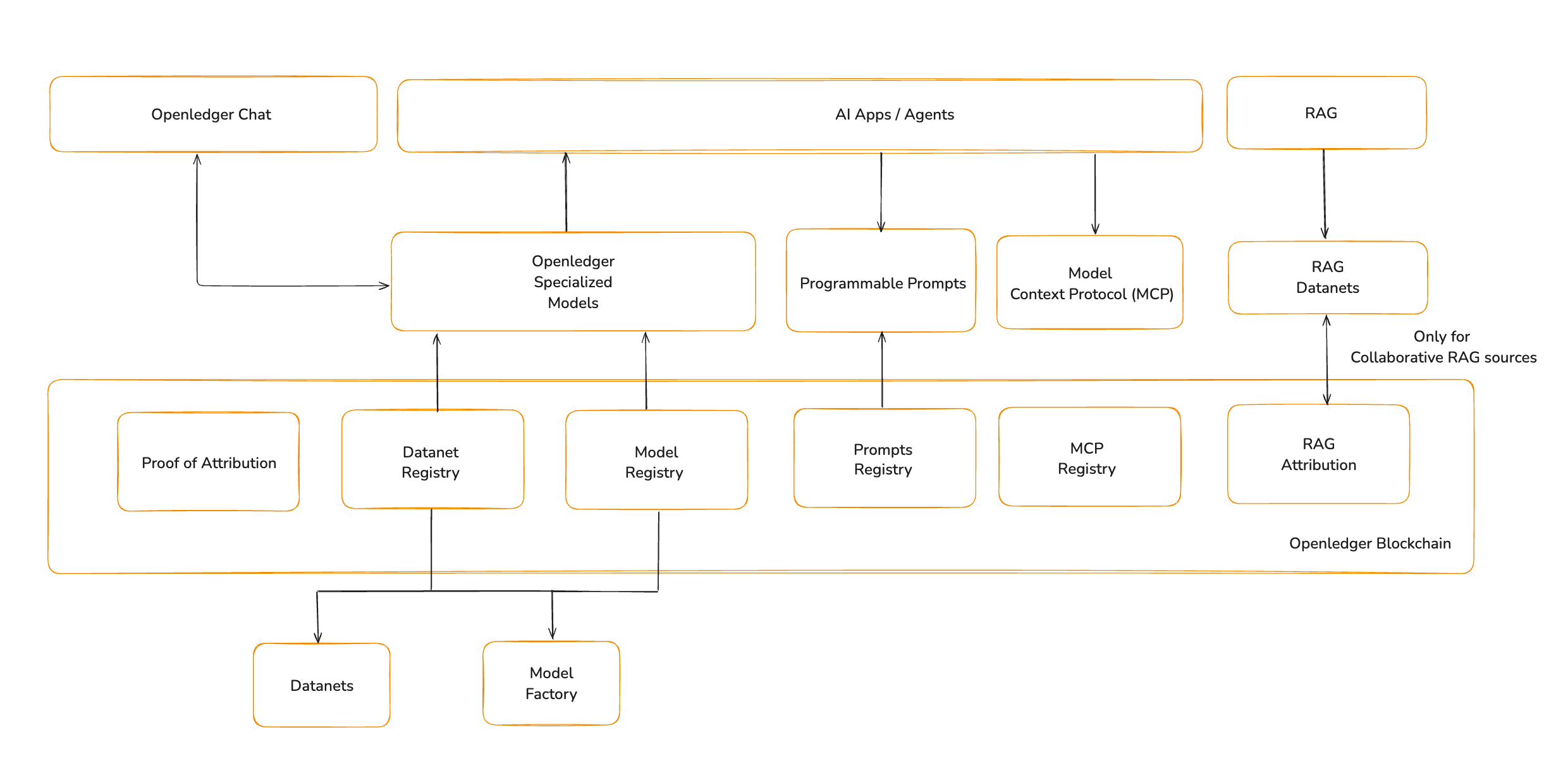
Spezialisierte Modelle (eine kurze Zusammenfassung)
Die Basis jeder intelligenten Anwendung ist ein Modell. Allgemeine Modelle bieten Flexibilität, aber wenn sie auf spezialisierte Bereiche angewendet werden, profitieren sie erheblich von Feinabstimmung und Anpassung. OpenLedger verbessert diesen Prozess durch eine dedizierte Pipeline:
-> Datanets, die kuratierte, kollaborative und attribuierbare Datenrepositorys sind, die von der Community aufgebaut wurden.
-> Model Factory, die die Feinabstimmung mit No-Code-Workflows vereinfacht.
-> OpenLoRA, das kosteneffektive Adaptervarianten hostet, die in Echtzeit umschalten können, wodurch Inferenz leichtgewichtig und komponierbar wird.
Diese Komponenten wurden in früheren Beiträgen ausführlich besprochen. Sie dienen als Grundlage. Und mit den richtigen Erweiterungen ermöglichen sie es, robuste, intelligente Agenten zu entwickeln.
Model Context Protocol (MCP)
Damit ein Modell eine Datei öffnen, eine Datenbank lesen oder ein Werkzeug aufrufen kann, benötigt es Zugriff auf den externen Zustand und Kontext. Um Modellen diese Fähigkeit zu geben, führt OpenLedger das Model Context Protocol (MCP) ein.
MCP definiert die Struktur zur Bereitstellung von Kontext für ein Modell und zum Erhalt strukturierter Antworten, die ausgeführt werden können. Es besteht aus drei Teilen: einem Client, der Daten bereitstellt, einem Server, der Werkzeugaufrufe verarbeitet, und einem Router, der den Fluss zwischen ihnen verwaltet.
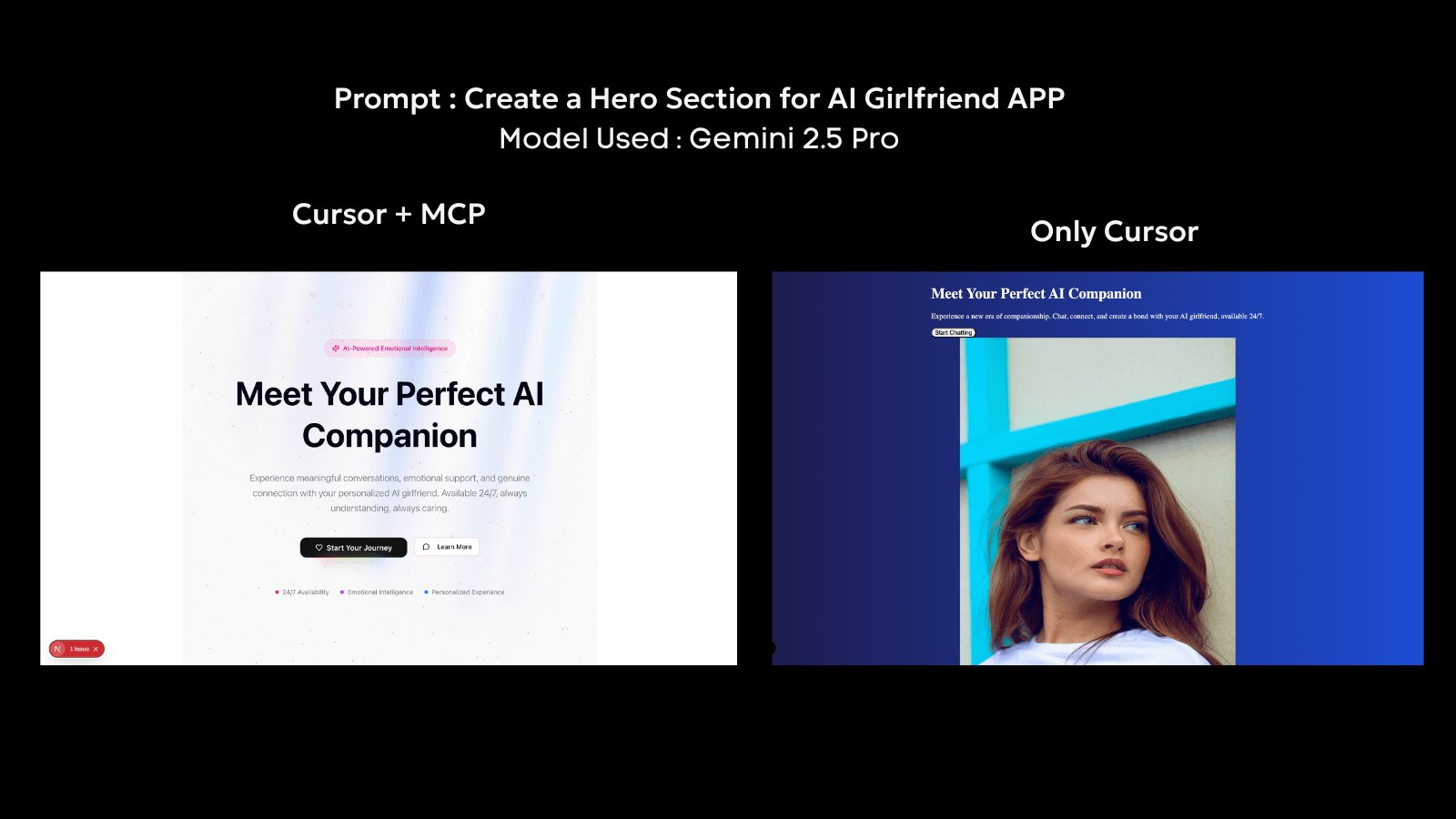
In der Praxis wurde MCP bereits in Systemen wie Cursor übernommen, bei denen ein Agent lokale Dateien lesen, Codebasen bearbeiten und werkzeugbasierte Aufgaben innerhalb der Entwicklungsumgebung durchführen kann. Werkzeuge wie 21.dev fungieren als MCP-Clients, die in Cursor integriert werden können, um dynamische, Echtzeitschnittstellen zu schaffen. Durch die Verwendung von 21.dev erlangen Agenten die Fähigkeit, an Live-UI-Komponenten zu arbeiten und Ausgaben zu generieren, die den Echtzeitstatus mit einer visuell reichen Schicht widerspiegeln.
Zukunftsvision für MCP mit OpenLedger
OpenLedger sieht vor, dass sich MCP zu einem Onchain-Register entwickelt. Jedes MCP-Werkzeug kann registriert, versioniert und attribuiert werden. Werkzeuge werden zu komponierbaren Komponenten, die jeder Agent aufrufen kann, wobei die Nutzung aufgezeichnet und on-chain belohnt wird. Dies ermöglicht Entwicklern, Dateileser, Renderer oder API-Clients zu veröffentlichen, die von jedem OpenLedger-basierten Agenten mit vollständiger Attribution und Rückverfolgbarkeit aufgerufen werden.
Retrieval-Augmented Generation
Einige Kenntnisse sind zu groß, zu detailliert oder zu häufig aktualisiert, um direkt in Modellgewichte eingebettet zu werden. Dennoch sind sie grundlegend für das Denken. Retrieval-Augmented Generation (RAG) erweitert die Fähigkeit eines Modells, indem es Echtzeit-, anfragen-spezifisches Gedächtnis einführt.
RAG trennt Speicherung von Inferenz. Dokumente werden in Vektoren eingebettet, semantisch indiziert und zur Laufzeit basierend auf der Benutzeranfrage abgerufen. Der abgerufene Inhalt wird dann in das Prompt-Fenster injiziert, wodurch die Antwort des Modells verankert wird.
Diese Methode ist besonders relevant für domänenspezifische Agenten. Ein Agent, der darauf trainiert ist, ein bestimmtes Gebiet zu verstehen, könnte auf Blogbeiträge, Dokumentationen, Vorschläge und Community-Threads zugreifen. Anstatt all diesen Inhalt zu memorieren, fragt er ein RAG-System ab, das aus vertrauenswürdigen Quellen aufgebaut ist. Die Antwort ist genau, aktuell und in realen Beweisen verankert. Diese Struktur ermöglicht es Agenten, Halluzinationen zu vermeiden, während sie in der Lage sind, dynamische Inhalte zu durchsuchen, abzurufen und zu schlussfolgern.
Zukunftsvision für RAG mit OpenLedger
OpenLedger erweitert RAG in eine kollaborative und attribuierbare Schicht. So wie bei Datensätzen und Modellen wird jedes Dokument, das in einem RAG-Index gespeichert ist, seinem Mitwirkenden zugeordnet. Wenn das Dokument abgerufen wird, wird diese Nutzung aufgezeichnet. Dies transformiert RAG von einem Gedächtnissystem in einen Anreizmechanismus.
In Zukunft werden Mitwirkende in der Lage sein, Dokumente on-chain als Teil eines verteilten Wissensgraphen zu registrieren. Jedes Abrufereignis wird Mikroattributionen auslösen und einen transparenten Fluss von Krediten und wirtschaftlichem Wert schaffen, der an informativen Einfluss gebunden ist.
Ein auf OpenLedger basierter Agent, der auf plattformspezifischen Inhalten wie Blogbeiträgen, Dokumentationen, Governance-Vorschlägen und Benutzerunterhaltungen trainiert wurde, muss nicht all den Kontext auswendig lernen. Er kann ein dezentrales RAG-System abfragen, das aus verifizierten Community-Quellen besteht. Jeder abgerufene Abschnitt verweist auf seinen Autor, was eine Belohnungsverteilung selbst zur Inferenzzeit ermöglicht.
Mit der Infrastruktur von OpenLedger wird RAG zu einem System für verifizierbare, incentivierte Logik. Jeder Absatz, jede Zitation oder jeder Datenpunkt kann zurückverfolgt, wiederverwendet und monetarisiert werden, auf eine Weise, die den tatsächlichen Einfluss im Agenten-Ökosystem widerspiegelt.
Prompts als Verhaltenslogik
Die letzte Schicht eines intelligenten Agenten ist sein Verhalten. Dies ist nicht in Gewichten oder Daten kodiert. Es wird durch Prompts definiert.
Ein Prompt strukturiert die Interaktion. Er sagt dem Modell, wie es denken, wie es seine Ausgabe formatieren und welche Einschränkungen es beachten soll. Er fungiert als logische Ebene, die regelt, wie Eingaben interpretiert und wie Werkzeuge aufgerufen werden. Bei komplexen Agenten ist das Prompt-Design keine einmalige Anweisung. Es kann Ketten strukturierter Vorlagen, dynamische Kontextfelder und Planungsanweisungen umfassen.
Prompt-Engineering ermöglicht es Entwicklern, das Verhalten von Agenten zu definieren, ohne das Modell selbst zu ändern. Mit dem richtigen Design werden Agenten in ihren Denkprozessen deterministisch. Ihre Ausgaben bleiben konsistent, die Werkzeugnutzung ist eingekreist, und die Antworten spiegeln sowohl den gegebenen Kontext als auch das beabsichtigte Ziel wider.
Zukunftsvision für Prompts mit OpenLedger
OpenLedger behandelt Prompts als programmierbare Assets. In Zukunft könnte dies zu einem Smart-Contract-Standard für Prompts führen, der es ermöglicht, sie direkt on-chain bereitzustellen, zu versionieren und zu referenzieren. Prompts würden zu erstklassigen Bausteinen in der Agentenentwicklung werden, mit Attribution und Wiederverwendbarkeit in ihr Design eingebaut.
Ein Prompt-Register auf OpenLedger würde Entwicklern ermöglichen, wiederverwendbare Vorlagen zu erstellen und zu veröffentlichen, die an spezifische Aufgaben, Werkzeuge oder Modelle gebunden sind. Diese Vorlagen könnten mit Agenten verknüpft, im Laufe der Zeit aktualisiert und basierend auf der Nutzung monetarisiert werden.
Jeder Prompt, der von einem Agenten verwendet wird, könnte auf seinen Autor zurückverfolgt werden. Die Attribution würde auf der Infrastrukturebene durchgesetzt werden, was faire Belohnungen, transparente Koordination und Interoperabilität auf Verhaltensebene zwischen Agenten ermöglicht. Prompts wären keine statischen Strings mehr, sondern dynamische, verifizierbare Komponenten intelligenter Systeme.
Fallstudie: Aufbau eines gemeinschaftlich trainierten Handelsagenten auf OpenLedger
So kann ein echter Handelsagent mithilfe von OpenLedger aufgebaut werden. Es beginnt mit Daten, baut das Modell, fügt Live-Werkzeuge hinzu und verwandelt sich in eine funktionierende Anwendung.
Schritt 1: Datensammlung der Community
Der Prozess beginnt mit einem Datanet. Ein Datanet ist eine Plattform zur Datenzusammenarbeit der Community. Trader aus Discord, Twitter und anderen Communities tragen Handelsstrategien, Chartannotationen, Tokenanalysen und Handelsentscheidungen bei. Der Datanet-Besitzer überprüft und verifiziert jede Einreichung. Nach Genehmigung werden die Daten zum Datanet hinzugefügt und Teil eines wachsenden Instruktionsdatensatzes. Jeder Beitragende wird on-chain aufgezeichnet.
Schritt 2: Ein spezialisiertes Modell trainieren
Mit den verifizierten Daten aus dem Datanet wird ein Modell feinabgestimmt, um Handelsmuster zu verstehen, wie Trader denken und wie Entscheidungen getroffen werden. Das Modell wird mit OpenLoRA bereitgestellt. Das hält das Modell leichtgewichtig, günstiger im Betrieb und einfach zu aktualisieren.
Schritt 3: Echtzeit-Kontext mit MCP hinzufügen
Der Agent benötigt Live-Marktdaten, um Entscheidungen zu treffen. Durch das Model Context Protocol (MCP) verbindet er sich mit:
-> CoinMarketCap für Tokenpreise
-> Binance und Coinbase für Echtzeithandel
-> Kaito für trendende Meinungen auf Twitter
-> Uniswap oder PancakeSwap für Onchain-Liquidität
Jedes Mal, wenn ein Werkzeug verwendet wird, wird die Attribution on-chain aufgezeichnet.
Schritt 4: RAG für Marktgedächtnis verwenden
Der Agent benötigt auch historischen Kontext. Mit Retrieval-Augmented Generation (RAG) zieht er Informationen wie:
-> Token-Whitepapers
-> DAO-Vorschläge
-> Governance-Entscheidungen
-> Emissionspläne
-> Aufzeichnungen über frühere Exploits oder wichtige Ereignisse
Dies gibt dem Agenten vollständiges Hintergrundwissen über die Tokens, die er analysiert.
Schritt 5: Agentenregeln als Prompts definieren
Prompts sagen dem Agenten, wie er alle Daten kombinieren und Entscheidungen treffen soll. Der Agent überprüft Preise, Liquidität, Sentiment und Token-Historie.
-> Wenn das Sentiment hoch ist, aber die Governance schwach oder es vergangene Probleme gibt, wird ein hohes Risiko angezeigt.
-> Wenn die Volatilität hoch ist und das Sentiment unklar, wird gewartet.
-> Wenn Fundamentaldaten und Sentiment stark sind, wird ein möglicher Einstieg vorgeschlagen.
Die Prompts sind versioniert, wiederverwendbar und vollständig attribuiert.
Schritt 6: Alles Onchain attribuieren
Jeder Datensatz, jedes Werkzeug, jeder Prompt und jedes Dokument, das vom Agenten verwendet wird, wird auf OpenLedger aufgezeichnet. Mitwirkende erhalten automatisch Anerkennung, wann immer ihre Arbeit eine Agentenentscheidung unterstützt.
Das Ergebnis
Community-Daten werden zu einem voll funktionsfähigen Handelsagenten. Er liest Live-Märkte, versteht die Token-Historie, wendet Logik an und trifft klare Entscheidungen. Alles, was er tut, ist transparent, rückverfolgbar und belohnt jeden beteiligten Beitragenden. So werden Agenten auf OpenLedger aufgebaut.
