ich habe das SIGN-Protokoll Litepaper und einige Integrationsdemos durchgesehen, hauptsächlich um zu verstehen, warum es immer wieder in Verteilungstools auftaucht. Auf den ersten Blick fühlt es sich ziemlich einfach an – einige Anmeldeinformationen definieren, diese verifizieren und dann verwenden, um zu entscheiden, wer Token erhält. So ähnlich wie die formalisierte Version der chaotischen Tabellenkalkulationen und Skripte, die Teams bereits verwenden.
und ja, ich denke, so sehen die meisten Menschen das. Eine Attestierungsschicht plus einige integrierte Airdrop-Mechaniken. Nützlich, aber nicht genau ein neues primitives Element.
aber das ist nicht das vollständige Bild.
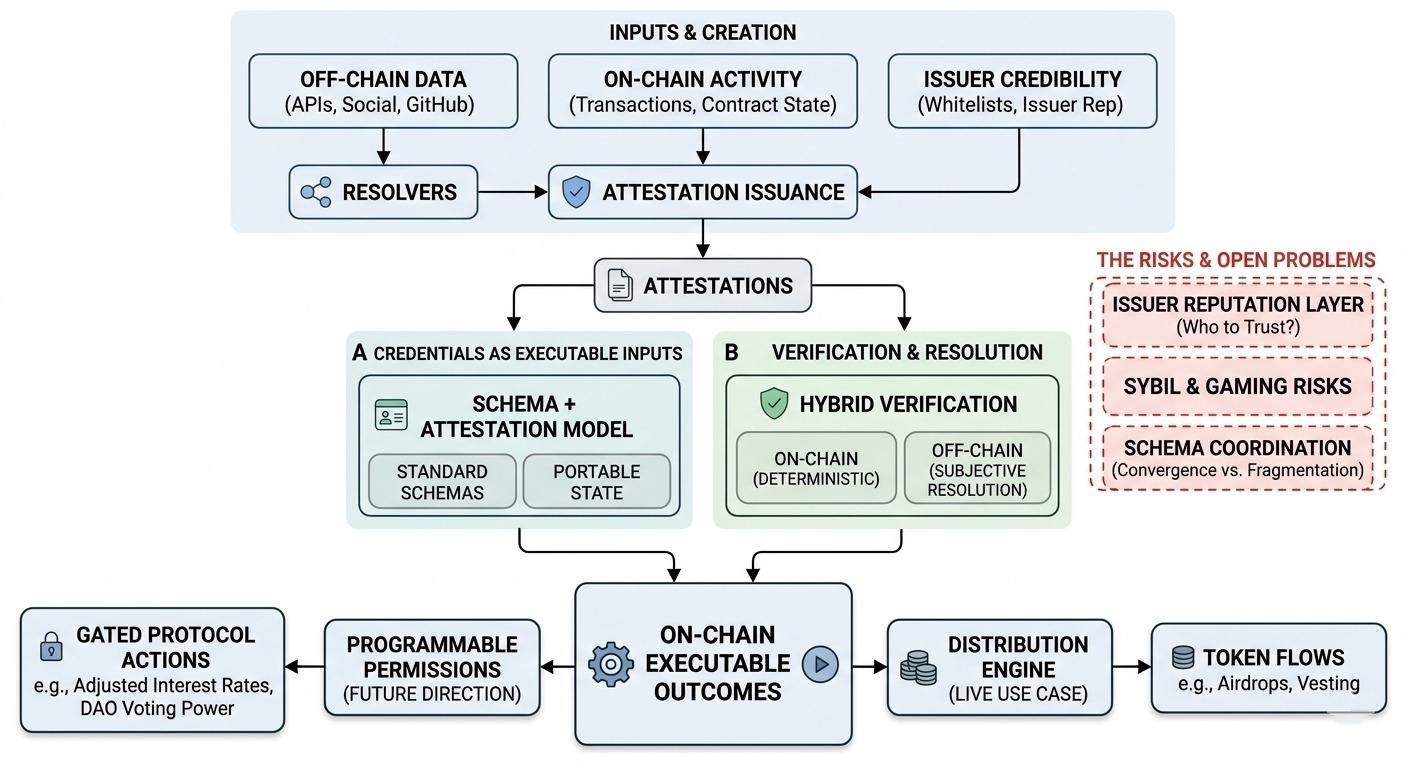
was SIGN still und leise tut, ist, Anmeldeinformationen in etwas Ausführbares zu verwandeln. nicht nur Datensätze, die man abfragt, sondern Eingaben, die direkt On-Chain-Ergebnisse steuern. und sobald Anmeldeinformationen Aktionen auslösen – insbesondere Tokenflüsse – hören sie auf, passive Daten zu sein, und verhalten sich mehr wie Infrastruktur.
das erste Stück ist das Schema + Bescheinigungsmodell. konzeptionell nichts Neues – Schemas definieren die Struktur, Bescheinigungen füllen sie mit Ansprüchen. aber SIGN setzt auf die Standardisierung von Schemas in einer Weise, die eine Wiederverwendung über Apps hinweg nahelegt. nicht nur „diese App definiert eine Anmeldeinformation“, sondern „diese Anmeldeinformation könnte unabhängig von einer einzelnen App existieren.“
und da wird es interessant. wenn Schemas tatsächlich geteilt werden, sehen Anmeldeinformationen wie tragbaren Zustand aus. die „Geschichte“ oder „Reputation“ eines Benutzers ist nicht an ein System gebunden. aber das hängt stark von der Koordination ab. Schemas sind nur wichtig, wenn mehrere Parteien ihnen zustimmen, und diese Zustimmung wird nicht durch das Protokoll durchgesetzt.
einige davon sind live – Projekte geben Bescheinigungen aus und verwenden intern Schemas. aber die plattformübergreifende Wiederverwendung fühlt sich immer noch dünn an. die meisten Teams scheinen zu definieren, was sie brauchen, und machen weiter, anstatt sich an gemeinsamen Standards zu orientieren.
der zweite Mechanismus ist die Verifizierungsschicht, insbesondere das hybride Modell. SIGN unterstützt sowohl On-Chain-Verifizierung (deterministisch, vertragsbasiert) als auch Off-Chain-Auflösung (externe Daten, APIs, Heuristiken). auf dem Papier ist das nur Flexibilität.
aber hier ist die Sache – die Mischung dieser beiden schafft eine gespaltene Vertrauensgrenze. On-Chain-Verifizierung ist einheitlich, jeder sieht dasselbe Ergebnis. Off-Chain-Auflösung führt Subjektivität ein, abhängig davon, wie Auflöser implementiert und gewartet werden.
also ist eine Anmeldeinformation jetzt nicht nur „wahr oder falsch“, sondern „wahr, je nachdem, wie man es auflöst.“ was für reale Daten in Ordnung ist, aber die Komponierbarkeit kompliziert. zwei Apps könnten dieselbe Bescheinigung konsumieren, aber zu leicht unterschiedlichen Schlussfolgerungen kommen.
dieser hybride Ansatz wird bereits verwendet, insbesondere bei Berechtigungsprüfungen, die auf Off-Chain-Signalen basieren. aber das Standardisieren des Verhaltens von Auflösungen oder sogar das Einigen auf akzeptable Variationen fühlt sich wie ein offenes Problem an.
das dritte ist die Verteilungsmaschine, die wahrscheinlich der konkreteste Teil heute ist. SIGN verbindet Anmeldeinformationen direkt mit der Token-Verteilungslogik. Berechtigungen über Bescheinigungen definieren und dann Verteilungen ausführen, ohne Listen zu exportieren oder benutzerdefinierte Skripte zu schreiben.
das ist eindeutig live und wird verwendet. es reduziert den operativen Aufwand und macht Verteilungen reproduzierbarer. aber es verschiebt auch, wo die Komplexität liegt. anstatt Verteilungen manuell zu skripten, kodierst du Logik in Schemas und Verifizierungsregeln.
und ich bin mir nicht ganz sicher, ob das immer einfacher ist – nur anders. Komplexität bewegt sich von ad-hoc-Skripten in strukturierte Definitionen, die einfacher wiederverwendbar sind, aber schwieriger zu verstehen, wenn etwas schiefgeht.
die zukunftsorientierteren Teile – persistente Identitätsschichten, plattformübergreifende Anmeldeportabilität, tiefere Wallet-Integrationen – fühlen sich eher wie Richtung als Realität an. sie hängen davon ab, dass Anmeldeinformationen in verschiedenen Ökosystemen wiederverwendet werden, was wiederum auf die Koordination von Schemas und das Vertrauen in die Aussteller zurückführt.
eine Sache, die ich immer wieder in Frage stelle, ist die Glaubwürdigkeit der Aussteller. wenn jeder Bescheinigungen ausstellen kann, benötigt das System irgendeine Möglichkeit, diese zu gewichten. ansonsten erhält man eine Flut von niedrigwertigen Anmeldeinformationen. SIGN setzt diese Ebene nicht durch – es überlässt es den Anwendungen oder zukünftigen Erweiterungen.
also hat man ein Problem zweiter Ordnung: nicht nur Anmeldeinformationen zu überprüfen, sondern zu entscheiden, welche Aussteller wichtig sind. und das kann schnell unordentlich werden.
außerdem frage ich mich, wie sich das unter adversen Bedingungen verhält. Sybil-Angriffe, kolludierende Aussteller, Schema-Gaming – keines dieser Probleme ist einzigartig für SIGN, aber das Protokoll erleichtert es, Anmeldeinformationen in großem Maßstab zu operationalisieren, was diese Probleme verstärken könnte.
neugierig auf:
* ob sich Schemas tatsächlich konvergieren oder projektbezogen fragmentiert bleiben
* wie sich Off-Chain-Auflöser entwickeln und ob sie standardisiert werden
* ob die Verteilung der Hauptanwendungsfall bleibt oder nur der Einstiegspunkt ist
* das Auftreten von Ausstellerreputation oder Filterebenen
* reale Beispiele für die Wiederverwendung von Anmeldeinformationen in nicht verwandten Ökosystemen
#signdigitalsovereigninfra @SignOfficial $SIGN