

Berichtsdatum: 2026-03-11
Beispielumfang: ClawHub Top 100 Fähigkeiten nach Downloads (Stand 10. März, 18:30 Uhr Pekinger Zeit)
Erkennungs-Engine: AgentGuard Fähigkeiten Sicherheits-Scan-Engine
Zweck des Scans: Um die grundlegende Sicherheitslage der beliebtesten AI-Agentenfähigkeiten zu bewerten und potenzielle Risiken wie Privilegienmissbrauch, sensible Operationen und bösartige Verhaltensmuster zu identifizieren.
📊 1. Executive Summary
Dieser Sicherheits-Scan führte eine umfassende Analyse der 100 am häufigsten heruntergeladenen Fähigkeiten im ClawHub-Ökosystem durch. Die Gesamtergebnisse sind wie folgt:
Insgesamt gescannte Proben: 100
Erfolgreiche Scan-Rate: 100 % (keine Parsing-Fehler oder fehlende Dateien)
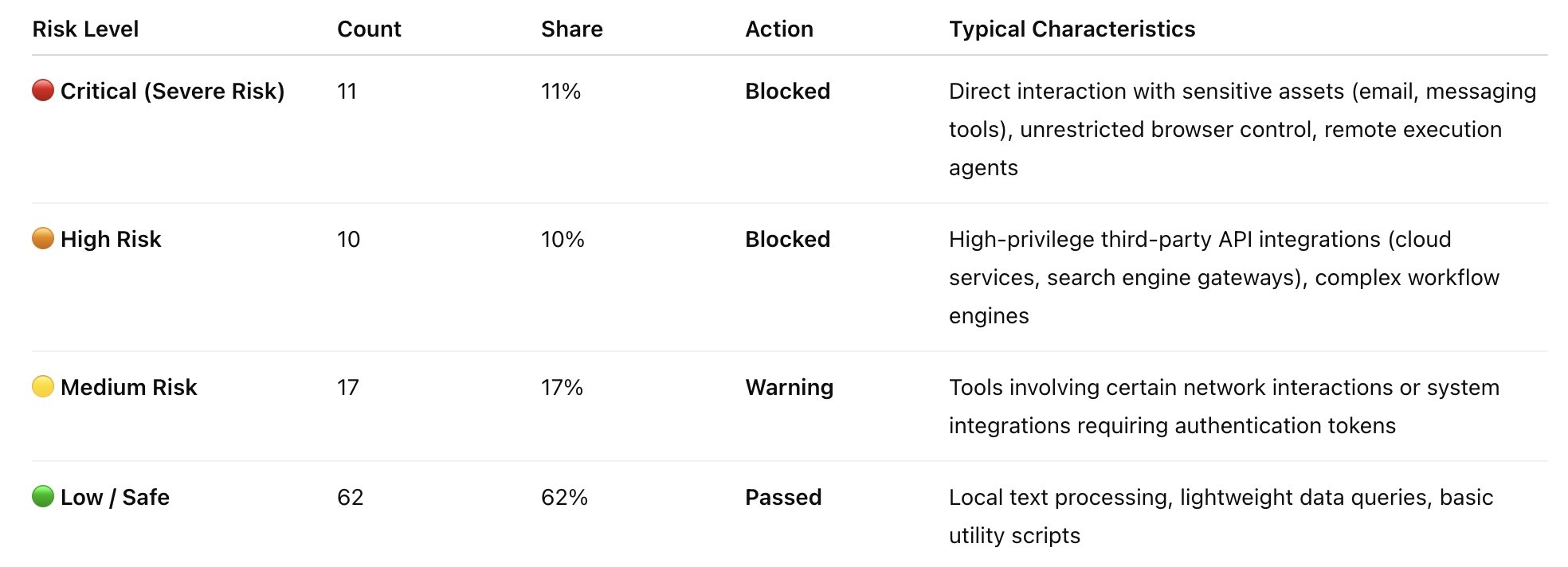
Blockierte Fähigkeiten: 21 (21 %)
Warnfähigkeiten: 17 (17 %)
Bestandene Fähigkeiten: 62 (62 %)

Hauptergebnis: Unter den Top 100 Fähigkeiten enthalten 21 % explizite hochriskante Operationen (wie direktes Netzwerk-Tunneling, sensible API-Aufrufe oder automatisierte Nachrichten). Für diese Fähigkeiten wird empfohlen, einen Human-in-the-Loop (HITL) Bestätigungsmechanismus vor der Ausführung durchzusetzen, um eine manuelle Überprüfung hochriskanter Aktionen sicherzustellen.
Darüber hinaus weisen 17 % der Fähigkeiten bestimmte Risikosignale auf und sollten mit Vorsicht ausgeführt werden. Für Benutzer mit strengeren Sicherheitsanforderungen wird auch empfohlen, eine manuelle Bestätigung für diese Fähigkeiten zu aktivieren.
📈 2. Risikostufenverteilung
Basierend auf dem AgentGuard-Regelsatz werden die Scananalyseergebnisse in vier Risikostufen kategorisiert, mit folgender Verteilung:
🚨 3. Hochriskante (Kritisch und Hoch) Fähigkeiten Analyse
In diesem Sicherheits-Scan wurden 21 Fähigkeiten direkt als blockiert klassifiziert, nachdem kritische oder hochriskante Regeln ausgelöst wurden. Diese Fähigkeiten fallen hauptsächlich in die folgenden hochriskanten operationellen Szenarien:
3.1. Headless-Browser und Automation (Browser-Automation)
Diese Fähigkeiten rufen typischerweise Puppeteer/Playwright oder verpackte CLI-Tools auf, die es dem Agenten ermöglichen, frei auf das Internet zuzugreifen.
Betroffene Fähigkeiten: agent-browser (Kritisch), agent-browser-clawdbot (Kritisch)
Erkennungsgrund: Erkennung der Kontrolle von Headless-Browser-Prozessen, Ausführung beliebiger JS-Skripte oder komplexer DOM-Interaktionen.
Risikowirkung: Kann für SSRF (Server-Side Request Forgery), interne Netzwerkproben, Umgehung von CAPTCHA-Schutzmaßnahmen für bösartiges Scraping oder Auslösen von Payloads von Phishing-Websites verwendet werden.
3.2. Kommunikation und Messaging (Kommunikation und Messaging)
Fähigkeiten, die direkt die E-Mail- oder Messaging-Tools der Benutzer steuern, um Nachrichten zu senden.
Betroffene Fähigkeiten: agentmail (Kritisch), whatsapp-business (Kritisch), imap-smtp-email (Kritisch), mailchimp (Hoch)
Erkennungsgrund: Erkennung von SMTP/IMAP-Protokoll-Keywords, Endpunkten für Massenmessungs-APIs und Kommunikations-Tokens mit hohen Rechten.
Risikowirkung: Wenn ein Agent durch einen Prompt-Injection-Angriff kompromittiert wird, könnten Angreifer diese Fähigkeiten nutzen, um Spam zu senden oder Social-Engineering-Betrügereien durchzuführen, was den Ruf der Benutzer schädigt und möglicherweise die Anforderungen an die Datenschutzkonformität verletzt.
3.3. Hochprivilegierte CRM- und Cloud-Ressourcen-APIs (Enterprise API Gateways)
Fähigkeiten, die Lese-/Schreiboperationen auf Unternehmens-SaaS-Plattformen über Proxy-Gateways durchführen.
Betroffene Fähigkeiten: google-workspace-admin (Kritisch), google-slides (Kritisch), feishu-evolver-wrapper (Kritisch), pipedrive-api (Hoch), youtube-api-skill (Hoch), trello-api (Hoch), google-meet (Hoch)
Erkennungsgrund: Die Regel-Engine hat REST-API-Anforderungsstrukturen erkannt, die in der Lage sind, sensible Daten zu ändern, sowie die Fähigkeit, den Zustand externer Systeme zu verändern.
Risikowirkung: Agenten können direkt grundlegende Unternehmensdaten wie Verkaufs-, Finanz-, Dokumenten- oder Medienvermögen (einschließlich der Gewährung oder Entziehung von Administratorrechten) ändern oder sogar löschen. Ohne strenge Human-in-the-Loop-Überprüfung könnten operationale Fehler zu erheblichen Verlusten führen.
3.4. Deep Search Engines und Scraping-Aggregation (Suche und Scraping)
Werkzeuge, die in der Lage sind, tiefgehende Inhalte zu crawlen und mehrfache Suchmaschinen zu aggregieren.
Betroffene Fähigkeiten: brave-search (Hoch), duckduckgo-search (Hoch), multi-search-engine (Hoch), tavily (Hoch)
Erkennungsgrund: Erkennung von hochfrequenten externen Netzwerk-Anforderungswrappern, HTML-Parsing und Scraping-Bibliotheken.
Risikowirkung: Neben möglichen IP-Sperren von Ziel-Websites kann unsichere Webinhaltsextraktion (wie das direkte Lesen von ungefiltertem HTML oder die Ausführung von Webseiteninhalten) indirekte Prompt-Injection-Risiken einführen.
3.5. Kernlogikänderung und Privilegieneskalation (Selbstmodifikation und Privilegieneskalation)
Fähigkeiten, die die Mutation des Verhaltens von Agenten, die Modifikation versteckter Konfigurationen oder den Zugriff auf systemweite Anmeldeinformationen beinhalten.
Betroffene Fähigkeiten: free-ride (Kritisch), moltbook-interact (Kritisch), trello (Kritisch), evolver (Hoch)
Erkennungsgrund: Erkennung von Schreibzugriffsanforderungen an Systemdateien (wie versteckten .json-Konfigurationsdateien), die Fähigkeit, lokale Anmeldeinformationen zu lesen, oder die direkte Verkettung sensibler Tokens in Bash-Befehlen.
Risikowirkung: Diese Fähigkeiten können die grundlegenden Verhaltensregeln des Agenten ohne Genehmigung ändern, bestehende Systembeschränkungen umgehen oder kritische API-Schlüssel aufgrund von Befehlsinjektionsanfälligkeiten offenlegen.
⚠️ 4. Risikoreiche (Mittel / Warnung) Fähigkeiten, die Aufmerksamkeit erfordern
Insgesamt wurden 17 Fähigkeiten als mittleres Risiko eingestuft. Die meisten davon sind Integrationsschnittstellen für Drittanbieteranwendungen. Obwohl die Scanning-Engine sie nicht direkt blockierte, gelten die folgenden Überlegungen:
Kalender- und Planungstools (caldav-calendar, calendly-api)
Produktivitäts- und Kollaborationstools (notion, x-twitter, xero, typeform)
Microsoft-Ökosystem-Integrationen (microsoft-excel, outlook-graph, outlook-api)
Dienstprogrammsammlungen (mcporter, asana-api, clickup-api)
Analyse: Das Hauptmerkmal dieser Fähigkeiten ist, dass ihre Funktionalität neutral ist, sie jedoch hochgradig wertvolle Anmeldeinformationen tragen. Der Sicherheits-Scan identifizierte, dass sie Zugriffstoken von Benutzern erfordern, aber keine explizite bösartige Logik auf Codeebene festgestellt wurde, sodass sie mit einer Warnung gekennzeichnet wurden. Wenn ein Agent jedoch dazu verleitet wird, diese Fähigkeiten zu verwenden (zum Beispiel, indem er angewiesen wird, „alle meine Meetings morgen zu löschen“ oder „dieses Notion-Dokument öffentlich zu teilen“), könnte dennoch erheblicher Schaden entstehen.
🛡️ 5. Zusammenfassung und Sicherheitsempfehlungen
Dieser Sicherheits-Scan zeigt, dass etwa 20 % der 100 am häufigsten heruntergeladenen Fähigkeiten auf ClawHub explizite hochriskante Operationen enthalten, was die Notwendigkeit zeigt, Sicherheits-Scans und Überprüfungen für Fähigkeiten durchzuführen.
Empfehlungen für Benutzer und Ökosystementwickler:
5.1. Verbesserung der Benutzerfreundlichkeit hochriskanter Fähigkeiten (Blockiert): Vermeiden Sie pauschale Verbote. Für wertvolle Fähigkeiten wie agent-browser und agentmail wird empfohlen, einen Human-in-the-Loop (HITL) Bestätigungsmechanismus vor der Ausführung durchzusetzen. Der spezifische Inhalt, der gesendet oder die auszuführenden Aktionen sollte angezeigt werden, und die Ausführung sollte erst nach ausdrücklicher Genehmigung des Benutzers fortgesetzt werden.
5.2. Schutz gegen „indirekte Prompt-Injection“ verstärken: Für alle als hoch markierten suchbezogenen Fähigkeiten muss der Inhalt, der an den Agenten zurückgegeben wird, strengen Bereinigungen unterzogen werden (wie das Entfernen von HTML-Tags und Skripten), um die Einspeisung bösartiger Inhalte von externen Webseiten zu verhindern.
5.3. Regelmäßige Sicherheitsüberprüfungen durchführen: Basierend auf den in dieser Analyse identifizierten Sicherheitsblindstellen sollten Maßnahmen wie Ändern spezifischer Konfigurationsdateipfade (z. B. AGENTS.md) und Aufrufen von System-Desktopsteuerbibliotheken sollten zur Liste hochriskanter Verhaltensweisen hinzugefügt werden. Alternativ können Entwickler die Sicherheitsinspektions- und Fähigkeiten-Scanning-Funktionen von AgentGuard verwenden, um regelmäßig die Sicherheitslage von Agenten und ihren Fähigkeiten zu prüfen.
👉Anhang: Detaillierte Ergebnisse des ClawHub Top 100 Skills Sicherheits-Scans
Klicken Sie auf den Link, um zu sehen:
https://inky-punch-9d2.notion.site/Appendix-Detailed-Results-of-the-ClawHub-Top-100-Skills-Security-Sca-3215da0dd7ad80719937c66b7c1225b3?source=copy_link