Mình bắt đầu để ý OpenLoRA từ một câu hỏi rất chán.
Không phải “AI agent sẽ thông minh đến đâu?”
Không phải “OpenLedger sẽ mở khóa data economy như thế nào?”
Mà là: nếu sau này có hàng nghìn model chuyên biệt, ai sẽ thật sự dùng chúng đủ nhiều để chúng sống được?
Nghe hơi mất hứng. Nhưng crypto đã dạy mình một bài khá đau: tạo ra supply luôn dễ hơn tạo ra demand. Tạo token dễ hơn tạo utility. Tạo asset dễ hơn tạo lý do để người khác quay lại dùng nó mỗi ngày. GameFi từng có quá nhiều vật phẩm không có người chơi thật. DeFi từng có quá nhiều vault chỉ sống nhờ emissions. AI crypto hoàn toàn có thể lặp lại lỗi đó, chỉ khác là lần này thứ nằm trong kho không phải NFT hay vault, mà là những model nhỏ được gọi là “specialized”.
Lúc đầu mình cũng suýt tin vào narrative đó quá nhanh.
Specialized AI nghe rất hợp lý. Một model cho audit smart contract. Một model cho trading research. Một model cho legal workflow. Một model cho từng cộng đồng có dữ liệu riêng. OpenLedger lại có Datanets để gom dữ liệu chuyên biệt, ModelFactory để fine-tune, Proof of Attribution để ghi nhận đóng góp. Nhìn trên giấy, mọi thứ nối vào nhau khá đẹp.
Nhưng cái đẹp trên giấy thường bỏ sót một câu rất đời: model đó có được gọi đủ nhiều không?
OpenLoRA làm mình khựng lại ở đúng chỗ này.
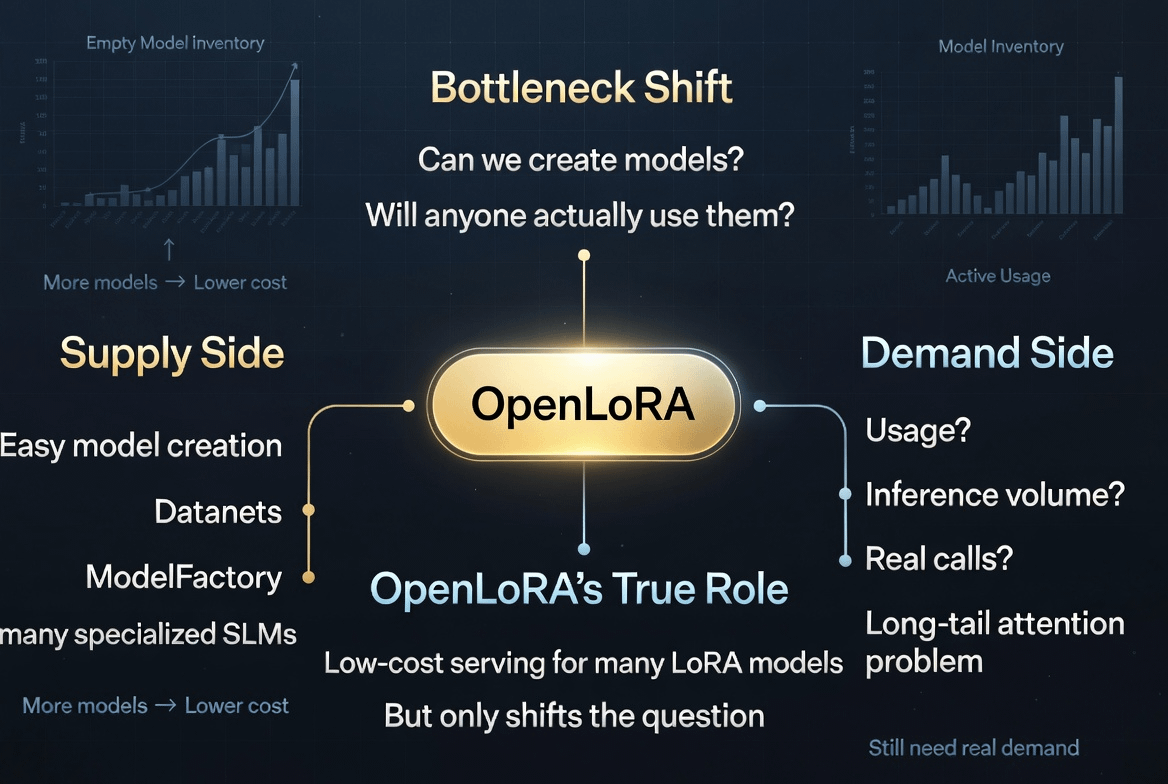
LoRA có thể hiểu đơn giản là một lớp điều chỉnh nhẹ gắn lên model gốc, thay vì phải huấn luyện lại cả một mô hình lớn từ đầu. OpenLoRA trong whitepaper được mô tả như một hệ multi-tenant để phục vụ các fine-tuned LoRA models với overhead thấp. Data point này nghe khô, nhưng nó quan trọng vì OpenLedger không chỉ cần tạo model. Nó cần làm cho rất nhiều model nhỏ có thể được chạy với chi phí đủ thấp.
Trước đây mình nhìn chi tiết này như một tối ưu hạ tầng. Bây giờ mình nghĩ nó giống một bài kiểm tra hơn.
Khi chi phí serving còn quá cao, ta luôn có lý do để biện minh: specialized AI chưa nở ra vì hạ tầng đắt, vì deploy khó, vì model nhỏ không đủ khả năng tự nuôi chi phí. Nhưng nếu OpenLoRA giảm được ma sát đó, câu hỏi thật bắt đầu lộ ra: liệu long-tail AI có demand thật không, hay chỉ có long-tail supply?
Đây là chỗ mình thấy OpenLoRA thú vị hơn chính phần kỹ thuật của nó.
Nó không chứng minh OpenLedger sẽ có một nền kinh tế AI bền vững. Nó chỉ dời bottleneck sang nơi khó trốn hơn. Từ “có chạy được nhiều model nhỏ không?” sang “model nhỏ nào có usage thật?” Từ “chi phí serving có quá cao không?” sang “inference volume có đủ dày để reward meaningful không?” Từ “ai tạo model?” sang “ai quay lại gọi model đó lần thứ hai, thứ mười, thứ một nghìn?”
Vì trong OpenLedger, một model chuyên biệt chỉ thật sự có đời sống kinh tế khi nó được dùng. Inference không chỉ là câu trả lời của AI. Nó là điểm nơi phí được trả, attribution có dữ liệu để đo, và reward có cơ hội quay lại contributor. Nếu usage mỏng, Proof of Attribution vẫn có thể đúng về logic, nhưng phần thưởng quay lại người đóng góp data có thể quá nhỏ để thay đổi hành vi. Công bằng trên sơ đồ không tự biến thành incentive ngoài đời.
Đây là đoạn mình nghĩ nhiều người sẽ bỏ qua.
Mọi người thích nói về “mở khóa thanh khoản cho data và model”. Nhưng thanh khoản không xuất hiện chỉ vì một tài sản được định nghĩa. Nó xuất hiện khi có người muốn dùng, muốn trả phí, muốn quay lại. Nếu không, hệ sinh thái có thể có rất nhiều adapter, rất nhiều model, rất nhiều dashboard đẹp, nhưng chúng giống một khu chợ mở cửa suốt đêm mà không có đủ người mua.
Mình không nói điều này để phủ định OpenLoRA. Ngược lại, đây là lý do mình thấy nó đáng quan sát. Một hạ tầng tốt không chỉ giải quyết vấn đề cũ. Nó làm lộ ra vấn đề tiếp theo. Nếu OpenLoRA giúp model nhỏ rẻ hơn để chạy, thì OpenLedger sẽ không còn được kiểm tra bằng số lượng model được tạo ra. Nó sẽ được kiểm tra bằng chất lượng demand phía sau những model đó.
Developer có tích hợp chúng vào workflow thật không?
Agent có gọi chúng vì chúng hữu ích hơn lựa chọn chung chung không?
Contributor có thấy reward đủ thật để tiếp tục đưa dữ liệu tốt vào Datanets không?
Hay tất cả chỉ tạo ra một lớp inventory mới cho thị trường định giá trước khi utility kịp xuất hiện?
Đây là nơi mình thấy OpenLoRA nối với một câu hỏi lớn hơn của AI crypto. Có thể vòng tiếp theo của ngành này không thiếu intelligence. Nó thiếu cơ chế để biết intelligence nào đáng tồn tại. Khi việc tạo và phục vụ model nhỏ trở nên dễ hơn, sự khan hiếm không còn nằm ở số lượng model. Nó nằm ở attention, distribution, trust và usage thật.
Vậy OpenLoRA không phải “câu trả lời cuối cùng” của @OpenLedger .
Nó giống lúc ta mở van trong một hệ thống đường ống. Trước đó, mọi người có thể tranh luận mãi rằng nước có chảy được không vì cái van quá chặt. Khi van mở ra, câu hỏi mới rõ ràng hơn nhiều: trong đường ống thật sự có nước không, và nước đó có chảy đến nơi có người cần không?
Nếu có, OpenLoRA có thể là một trong những chi tiết âm thầm giúp long-tail specialized AI trở thành kinh tế thật.
Nếu không, long-tail intelligence sẽ chỉ trở thành một kho hàng dài vô tận của những model ít ai gọi.
Và mình nghĩ đó mới là bài kiểm tra đáng nhìn ở OpenLedger. Không phải dự án có thể tạo ra bao nhiêu model nghe hay trên giấy, mà là bao nhiêu model có thể được gọi đủ nhiều để dữ liệu phía sau chúng không chỉ được ghi nhận, mà thật sự có dòng giá trị quay lại.